Preamble
When you run SELECT COUNT(*), the speed of the results is heavily influenced by the database’s structure and settings. Let’s conduct a survey of the Votes table in the 300 GB version of the 2018-06 Stack Overflow database, which has 150784380 rows and takes up about 5.3 GB of space.
For each method, I’m going to take three measurements:
- (With SET STATISTICS IO ON installed) How many pages it reads.
- When statistics time is enabled, how much CPU time it consumes
- How quickly does it move?
Do not focus on minute operational differences; I am writing this post to illustrate the distinctions between general features and the operation of my theory. You may obtain different results in your environment due to variations in the iron, system version, etc., and this is beneficial.
Depending on your own performance requirements, there are additional aspects of these methods as well, including memory allocation, the capacity to operate without locks, and even the precision of the answers in challenging queries. I won’t discuss locks or isolation levels in relation to our tests.
I execute these tests on an 8-core virtual machine with 64G RAM using SQL Server 2019 (15.0.2070.41).
Plain COUNT (*) only with clustered line storage index and compatibility level 2017 and earlier
ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 140; GO SELECT COUNT(*) FROM dbo.Votes; GO
The Votes table can be stored entirely in a cache on my SQL Server since it is only 5.3GB in size. Even after the first query and data caching in RAM, it is still not fast:
- Reading pages: 694389
- CPU: 14.5 seconds processor time
- Duration: 2 seconds
Compatibility Level 2019 (batch mode on line indices)
ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 150; GO SELECT COUNT(*) FROM dbo.Votes; GOIn SQL Server 2019, there are batch mode operations on string indices, initially available only on column indexes. The benefits here are quite large, although we still deal only with string indices.
- Reading pages: 694379
- CPU: 5.2 seconds processor time
- Duration: 0.7 sec.
A sharp reduction in CPU time is due to batch mode. This isn’t clear in terms of how it works until you move the mouse over each operator:
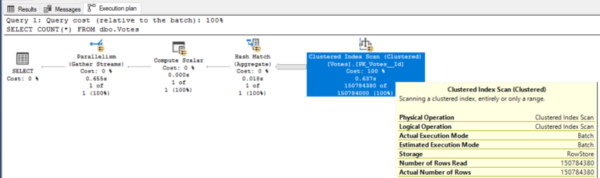
Batch mode is great for when you have a lot of requests that all generate reports and add up to a lot of data.
Adding non-clusterized string indices, but using mode 2017 and earlier
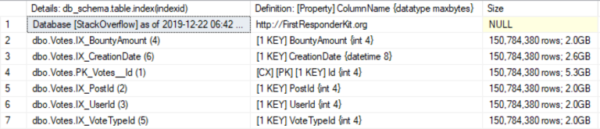
I’m going to make an index for each of the DBO’s five columns. Votes table and then compare their sizes using sp_BlitzIndex:
CREATE INDEX IX_PostId ON dbo.Votes(PostId); GO CREATE INDEX IX_UserId ON dbo.Votes(UserId); GO CREATE INDEX IX_BountyAmount ON dbo.Votes(BountyAmount); GO CREATE INDEX IX_VoteTypeId ON dbo.Votes(VoteTypeId); GO CREATE INDEX IX_CreationDate ON dbo.Votes(CreationDate); GO sp_BlitzIndex @TableName = 'Votes'; GOCheck the number of rows in each index relative to its size. When SQL Server needs to calculate the number of rows in a table, it is intelligent enough to look for the smallest object and then use that to calculate.
Indexes can have different sizes depending on the data types of the indexed content, the size of the content of each line, the number of NULL values, etc.
I will return to Compatibility Level 2017 (removing the batch mode operation) and then do the counting:
ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 140; GO SELECT COUNT(*) FROM dbo.Votes; GOSQL Server chooses the BountyAmount index, one of the smaller 2Gb:
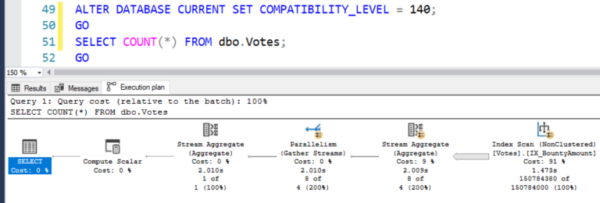
Even though we read 150M fewer lines because we read fewer pages, the processor time and duration remain unchanged:
- Reading pages: 263322
- CPU: 14.8 seconds processor time
- Duration: 2 seconds
If you want to reduce the CPU time and duration, you really need a different approach to counting, and batch mode operation will help.
Batch mode 2019 with unclustered string indices
So, let’s now test the batch mode operation with the available indexes:
ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 150; GO SELECT COUNT(*) FROM dbo.Votes; GO
Here we still use the BountyAmount index and make the same number of reads as in variant #3, but we get a shorter processor time and step #2 duration:
- Page Reading: 694379
- CPU: 4.3 seconds processor time
- Duration: 0.6 seconds
So far, it’s a winner. But let us remember that the batch mode was originally implemented in connection with column indexes, which are excellent tools for querying report generation.
Non-colonstructed column index with batch mode
I am intentionally working here in 2017 compatibility mode to find out what the reason is.
CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_BountyAmount ON dbo.Votes(BountyAmount); GO ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 140; GO SELECT COUNT(*) FROM dbo. Votes; GO
The scan operator for our new column index is in the execution plan. All of the operators in the plan refer to batch mode:
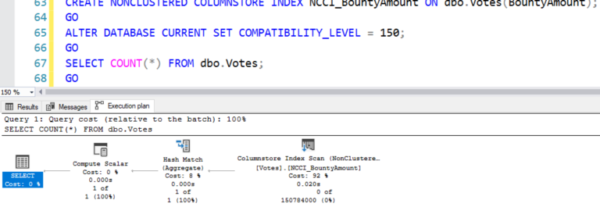
This is where I have to change the units of measurement:
- Reading pages: 73922
- CPU: 15 milliseconds
- Duration: 21 milliseconds
Prospects: I know some developers who try to use system tables to quickly count the number of rows, but even they can not achieve such results in speed.
What you need to do to get SELECT COUNT(*) queries done quickly
The best outcomes are presented first, in descending order of preference and speed:
- Have a column index built on the table and use SQL server 2017 or a newer version.
- Read about column indexes, especially those Niko articles that mention the word “batch” in the title, to get to know the specifics, and build a column index on a table if you have any version that supports batch mode on column indexes.
- Even with string indices, you can significantly reduce CPU usage by using batch mode on line storage. This is really simple to implement – you’ll probably only need a few changes to your application and database schema. However, you won’t get the surprisingly quick millisecond responses that a column index can provide.
About Enteros
Enteros offers a patented database performance management SaaS platform. It finds the root causes of complex database scalability and performance problems that affect business across a growing number of cloud, RDBMS, NoSQL, and machine learning database platforms.
The views expressed on this blog are those of the author and do not necessarily reflect the opinions of Enteros Inc. This blog may contain links to the content of third-party sites. By providing such links, Enteros Inc. does not adopt, guarantee, approve, or endorse the information, views, or products available on such sites.
Are you interested in writing for Enteros’ Blog? Please send us a pitch!
RELATED POSTS
Enteros and Cloud FinOps: Driving Database Performance and Observability in the Financial Sector
- 19 February 2025
- Database Performance Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Optimizing Cost Estimation in the Tech Sector: How Enteros Leverages Logical Models and Cloud FinOps for Smarter Database Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Enteros and Cloud FinOps: Transforming Database Performance and Observability in the Real Estate Sector
- 18 February 2025
- Database Performance Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Optimizing Database Performance for EdTech Firms: How Enteros Enhances RevOps with Advanced Database Performance Software
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…