MongoDB: count, group, distinct

MongoDB grouping commands: count, group, distinct should be considered separately.
Number of items in the collection
With the count() function you can get the number of elements in the collection:
db.users.count()
You can group the search options and the count function to calculate how many specific documents, such as those with name=Tom:
db.users.find({name: "Tom"}).count()
Moreover, we can create chains of functions to concretize the counting conditions:
db.users.find({name: "Tom"}).skip(2).count(true)
It should be noted here that by default the count function is not used with the limit and skip functions. To use them, as in the above example, the Boolean value true must be passed to the count function.
MongoDB Function
A collection may have documents that contain the same values for one or more fields. For example, several documents have a name: “Tom”. And we need to find only unique, different values for one of the fields of the document. To do this, we can use a distinct function:
db.users.distinct("name")
["Tom", "Bill", "Bob"]
Here I request only unique values for the name field. And on the next line, the console outputs the found unique values as an array.
MongoDB Grouping and the group method
Using the group method is similar to using GROUP BY expression in SQL. The group method accepts three parameters:
- key: indicates the key on which the grouping should be performed
- initial: initializes the fields of the document that will represent the group of documents
- reduce: represents a function that returns the number of elements. This function takes as its arguments two parameters: the current element and the aggregate result document for the current group
- keyf: an optional parameter. It is used instead of the key parameter and represents a function that returns a key object
- cond: optional parameter. It is a condition that should return true, otherwise, the document will not take part in the grouping. If this option is not specified, all documents will be grouped.
This parameter is optional. Represents a function that is triggered before the grouping results are returned.
For example:
db.users.group ({key: {name : true}, initial: {total : 0},
reduce : function (curr, res){res.total += 1}})
Let’s parse the expression. The key parameter indicates that the grouping will be performed with the key name: key: {name: true}.
The value of the initial parameter initializes the fields of the resulting document that will represent the group. Thus, in this case, the initial value of the total field is set. This field will represent the number of elements for the group. And since there may be no elements, we initialize it with zero.
The parameter reduction represents a function where curr refers to the current object in the group, and res represents the current group. If another object with a certain value for the name field is found, this document is added to the group, and the value of total is increased by one in the res document.
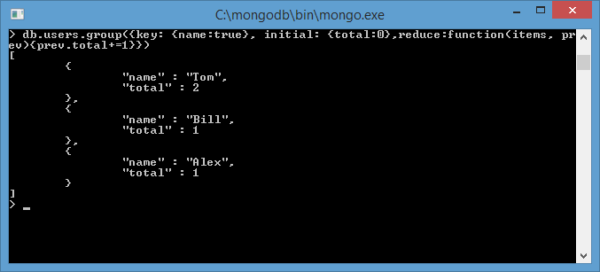
As can be seen from the screenshot, there are two documents in the user’s collection with name=Tom, and one document each with name=Alex and name=Bill.
When using grouping, you should consider that the group function does not work in sharded clusters. In this case, the map-reduce function should be used instead of the group function.
Aggregation Example: $group and $count – MongoDB Aggregation Tutorial
Enteros
About Enteros
IT organizations routinely spend days and weeks troubleshooting production database performance issues across multitudes of critical business systems. Fast and reliable resolution of database performance problems by Enteros enables businesses to generate and save millions of direct revenue, minimize waste of employees’ productivity, reduce the number of licenses, servers, and cloud resources and maximize the productivity of the application, database, and IT operations teams.
The views expressed on this blog are those of the author and do not necessarily reflect the opinions of Enteros Inc. This blog may contain links to the content of third-party sites. By providing such links, Enteros Inc. does not adopt, guarantee, approve, or endorse the information, views, or products available on such sites.
Are you interested in writing for Enteros’ Blog? Please send us a pitch!
RELATED POSTS
Optimizing Database Performance and Cloud FinOps in the Insurance Sector with Enteros and AWS CloudFormation
- 3 April 2025
- Database Performance Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Driving Growth and RevOps Efficiency in the Technology Sector with Enteros
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Enhancing Healthcare Efficiency with Enteros: AIOps-Driven Database Performance Monitoring
- 2 April 2025
- Database Performance Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Optimizing Cost Estimation and RevOps Efficiency with Enteros: Enhancing Financial Stability and Balance Sheet Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…