Preamble
Does our PostgreSQL monitoring tool pgwatch2 work with managed cloud database service providers, such as Google Cloud? This question is pretty frequently asked. Well, the quick response is, “Yes, we scan!” However, the devil is always in the details, so you should be aware of a few subtleties or extra steps.
I’ve put together a brief “how-to” on using pgwatch2 with Google Cloud’s PostgreSQL offering as an example of a managed database service in order to clarify the subject and to slightly document the procedure.
However, we haven’t personally tested out all the most recent or specialized cloud providers, so I wouldn’t offer a 100% guarantee on that promise. Instead, I’d offer a 99.9% guarantee.
In addition, pgwatch2 is one of the most well-known Open Source Postgres-specific monitoring tools available, if the name doesn’t sound too familiar. It offers a wide range of adaptable deployment options, metric fetching capabilities, and data stores. The project’s official documentation contains more details. If you would rather look at the code, head over to Github.
Managed cloud databases – pure magic?
But before we get hands-on, what exactly is a managed database service, such as the one provided by Google Cloud SQL in this instance? Why shouldn’t it function?
It might not be immediately obvious to those who don’t deal with database systems on a daily basis that, in most cases, what you get after clicking “$mydb > Next > Next > Launch” or its equivalent is actually very similar to a stock PostgreSQL instance! In other words, you’re getting almost the same thing that you would get when typing apt install postgresql on your server or workstation, at least in standard SQL matters of schema and data management, i.e. for DDL and DML.
The biggest change (aside from the positive aspects like high availability, backups, and updates being handled automatically) is actually that security-sensitive features are being removed from you, such as not being given a real superuser account with the power to run arbitrary commands on the operating system level! Which, I must admit, is a scary thing. If you’re not sure what I mean, you can read more about that here. But there are also other reasons, such as the fact that advanced configuration features are being taken away. In essence, the following groups could be used to summarize the limitations:
OS inaccessible
Obviously, it’s well justified to disable arbitrary command execution with COPY PROGRAM or archive_command — but this also includes no file system access via pg_ls_dir(), etc. That would hint at implementation details or provide extra information for possible attack vectors to break out of the so called “sandbox”.
limiting the configuration of the server to a limited set of variables and ranges
Here, the main argument is that you shouldn’t act recklessly and should stick to the hardware resources that you have reserved. The built-in Logical Replication feature of PostgreSQL, which essentially enables relatively painless, nearly zero downtime migration to another service provider or to a self-managed full-featured Postgres instance, is one of the more cunning considerations, however, and it is disabled. If the idea is unfamiliar to you, feel free to read more about it here.
Control of access security
This covers limiting/controlling both the pg_hba.conf infrastructure so that for example SSL is always required or access is guaranteed to be possible only from within that cloud account, and also aspects like limiting the “pseudo-superuser” so that, by default, it does not even see other people’s running queries.
limited options for extensions
Since it takes a lot of work to review the code and ensure that it is stable and secure, all cloud providers, including Google Cloud, only permit a small whitelist of pre-approved extensions to be activated, typically those extensions from the official “contrib” package. There are countless excellent PostgreSQL extensions available, and this extensibility infrastructure is the key to PostgreSQL’s steadily increasing popularity. While this is obviously understandable, it’s also the thing that irritates me the most about the managed services.
However, it’s not all bad; there are other features that, particularly for less experienced or casual database users, make them a good choice. These features include hiding complexity like HA/failover, backups, server configuration, and offering some fundamental metrics.
Why use an external monitoring tool with your cloud database?
The big question is: Why would one use an additional tool at all when all managed service providers offer some sort of performance metrics and dashboards out of the box, which in the case of Google’s offering actually looks pretty decent (it goes by the name of “Query insights”)?
I suppose I can come up with some good ones:
Familiarity
The old saying, “You can’t teach an old dog new tricks,” probably holds some truth. People typically do not want to constantly work with new tools that are only marginally better than old ones, as their utility is ultimately limited by what the Postgres engine can offer in terms of instrumentation.
Unification/integration
What if your company uses many different cloud database service providers in addition to running some self-managed ones? Do you really want to keep up the mental burden of having to translate between different vocabularies and remember all the specifics of the various providers, as it is obvious that cloud providers have not been able to agree on a common glossary? Not to mention constantly logging into various environments or looking for the right browser tab, having a single tool that contains all the metrics from various systems is clearly a better option in this situation.
regulated accessibility to metrics
What if the members of your development team lack access to the service provider’s graphs/API because of strict security measures? What if you have some freelance consultants on your team and you only want to show them a subset of the relevant metrics? It may be preferable in these circumstances to gather, manage, and expose metrics in accordance with your own rules.
options for advanced configuration and added features
Because managed services have such a large user base, their implementation is typically quite straightforward. People who don’t have much experience with databases but only need a data store for the application they care about need to be able to jump in and start working right away. Again, database professionals who need to see more specific data may not find this to be ideal.
What if you are unable to adjust the frequency of the background metrics collection by your cloud provider? What if you preferred a different display option for your graphs, such as a table? What if you require all of PG’s available metrics? Here, using third-party tools will give you a lot more flexibility.
Alerting
Making it simple to set up fundamental alerts is one area where cloud service providers, for whatever reason, have not yet done their best. For “cloud migrants,” having a flexible and user-friendly interface like Grafana would be extremely beneficial.
Despite all the good things said, sadly, nothing is perfect. We don’t have easy access to the OS-level metrics, which is another major drawback of external tools when it comes to managing databases! This data is usually stored somewhere in the behemoth’s stomach and can be pulled out using an API, but you usually have to write your own code to do that. As an alternative, it can also be integrated to be fetched on the fly with just a little bit more lag with some tools, like Grafana once more, which supports mixed datasource graphs. However, retention rules might still be an issue if you want to occasionally review data that is several months old.
Having options is a good thing, and I wouldn’t want to rely solely on my cloud provider to know what is best for me, to put it briefly. For more significant databases, at least.
Launching a managed Google Cloud SQL database in a PostgreSQL variation
At first, I considered skipping this section… Since the GUI is actually quite straightforward and well-designed, everything should be obvious. I’ll post screenshots about those because there were a few configuration sections where I had to take a moment to stop and think.
The problem is that the largest cloud providers all offer a variety of managed database engines, and in an effort to standardize the language, they might have chosen language that, in the case of PostgreSQL, is not immediately clear. For example, the term “flags” refers to PostgreSQL server configuration parameters!
a brief overview of setting up your first Cloud SQL database
Please take note that I am not covering the prerequisite steps of opening an account, connecting a credit card, etc.
- Locate the appropriate software or database engine (since Google also works with MySQL and SQL Server).
- Give the instance a name that has personal meaning for you.
- Select the hardware, high-availability class, region where the actual server will be located, and Postgres version.
- However, keep in mind that you can still use some Google cloud-specific tricks, like the Cloud Proxy. In the “Connections” section, you can specify network ranges that are permitted to access the instance. By default, there is no access from machines within the same account/VPC.
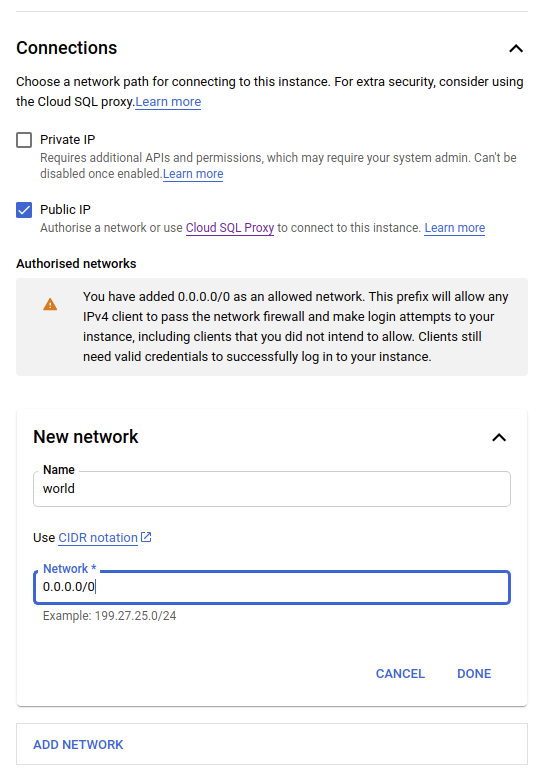
- Optional step: Enable the “Query insights” feature under advanced options (“Customize your instance”) to activate automatic Google engine collection of common Postgres metrics, in case you don’t intend to use any additional monitoring tools or just want to have it available as a fallback option.
- It’s recommended to create some standard “non-admin” user accounts for DDL and DML management after pressing “Create instance” and after the database is ready for connections. After that, it’s pretty much business as usual.
Creating a monitoring user
Because we’re only interested in monitoring, it’s not a good idea to use the default admin/superuser account over a remote connection. Instead, we’ll need to add a step and create a monitoring role for the pgwatch2 metrics collector. Fortunately, the Postgres project now supports that typical monitoring requirement as of version 10. There’s a special system grant called pg_monitor for that purpose that elevates the privileges just a bit! The steps below are listed in the documentation and also on Github’s mini-how-to.
GRANT pg_monitor TO pgwatch2; CREATE USER pgwatch2 WITH PASSWORD "secret" -- pg_monitor is a special system role for metrics access.
Configuring pgwatch2 to monitor a Google Cloud instance
I won’t go into detail about installing pgwatch2 here; refer to the documentation instead. Basically, all we need is a straightforward YAML configuration file once the metrics agent and the metrics storage database are set up (Postgres with TimescaleDB is recommended!).
No issues are anticipated, and it should just work, as I mentioned in the introduction. Given that you’re using the correct configuration, of course. And here, given the rising popularity of managed cloud services, we’ve now made things on the pgwatch2 side pretty simple with some preset configurations tuned for different engines! In the case of Google Cloud, an example YAML configuration entry should make use of a preset configuration with the name “gce” (assuming a file-based installation). Consequently, it should resemble this:
- unique_name: gce_mon dbtype: postgres # use postgres-continuous-discovery here if want to monitor all Dbs, # optionally according to a regex pattern host: 1.2.3.4 # paste your real IP/hostname here port: 5432 dbname: postgres # monitoring a single DB only here user: pgwatch2 password: # actual password is in the .pgpass file stmt_timeout: 5 # seconds preset_metrics: gce is_enabled: true sslmode: require
Once that is established, we can test-start the pgwatch2 metrics collector and determine whether it functions properly:
$ pgwatch-daemon -c /etc/pgwatch2/config/instances.yaml --datastore=postgres –pg-metric-store-conn-str=”postgresql://pgwatch2@localhost:5432/pgwatch2_metrics” 2021/05/06 14:10:05 WARN main: --metrics-folder path not specified, using /etc/pgwatch2/metrics 2021/05/06 14:10:06 ERRO MetricGathererLoop: Failed to fetch metric data for [gce_mon:stat_statements_calls]: pq: relation "pg_stat_statements" does not exist 2021/05/06 14:10:06 ERRO MetricGathererLoop: Failed to fetch metric data for [gce_mon:stat_statements]: pq: function get_stat_statements() does not exist
I see some mistakes. You might think that this doesn’t look good for a “preset config,” but in this case, it’s actually expected for a completely new and pristine instance because Postgres isn’t fully pre-configured for thorough out-of-the-box monitoring—a few small changes are needed, which are covered in the next chapter.
If you’d like to see more details on these errors, or in general see what pgwatch2 is actually doing, then set the --verbosity parameter to info level. There’s also a debug level, but that’s meant rather for bug tracking/developing and will overflow you with information.
Configuring the Google Cloud instance for maximum monitoring benefit
In essence, we must take two actions. The first is a “must have” for all Postgres databases that might experience performance issues at some point or where we need to be able to see which user actions are actually being performed more frequently. The second one is more of a “nice to have,” but I always make sure it is enabled on hardware that is at least moderately up to date. You won’t experience any problems without it; it will just make some of the preset Grafana dashboards provided by the pgwatch2 project appear a little less full.
An admin account should be used to create the “pg_stat_statements” extension.
For most managed services, the extension itself is already activated and present in shared_preload_libraries – if not, you most definitely are allowed to activate it, as it’s the single most useful extension for performance troubleshooting and comes bundled with Postgres by default. Note that you need to run the code below for each database you want to keep an eye on.
EXTENSION CREATE pg_stat_statements;
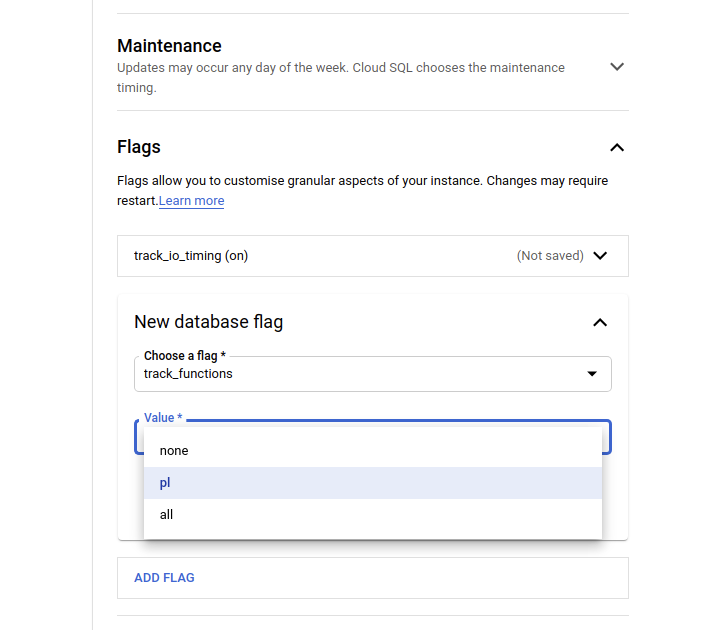
Make changes to/verify that the server configuration tracks IO timings and stored procedure execution times.
Basically, we need to enable the track_io_timing parameter and set track_functions to at least pl. Note that the all setting is normally not needed unless you plan to optimize some C functions coming in from extensions. For the Google service this would look something like what you see below – remember, server configuration parameters/settings are called “flags” on Google Cloud!
Pgwatch2 users and Grafana
We can now launch Grafana to view some lovely graphs now that our metrics collection daemon has been running for some time. One of the main reasons why users prefer pgwatch2 is that it makes delving into the metrics incredibly simple. This is made possible by the usability and features of Grafana as well as a variety of ready-made dashboards to cover all common monitoring needs. It only takes a few clicks to change the visual side, which is not possible with the tools offered by cloud vendors!
When starting from scratch, the pgwatch2 dashboards must be imported into Grafana. The documentation here says that this can be done manually “per dashboard” or automatically with an “import all” script.
Basically, the majority of dashboards should work as when monitoring a local setup – just some dashboards like the “Systems Stats” will be unusable and empty because we cannot create PL/Python helpers on the managed server to extract CPU load, etc.
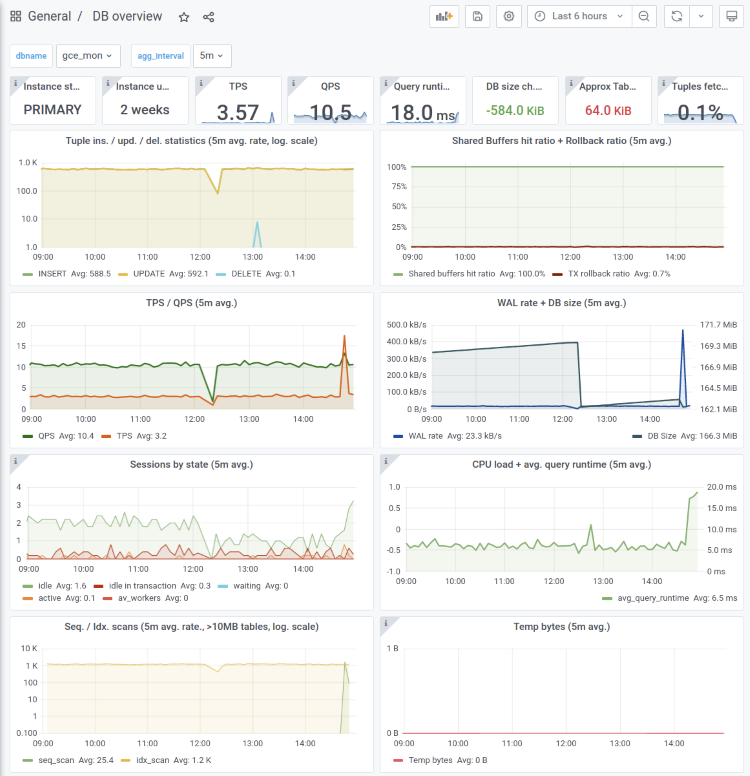
The “DB overview unprivileged” dashboard was made for situations where the metrics agent might not have full access. You might prefer to use it instead of the default “DB overview” dashboard, which is usually used as a starting point when reports of strange database behavior come in. In this case, we only show metrics that are always there, even for plain users with only a CONNECT privilege. It looks like the following:
Summary
Let’s sum it all up! As we have seen, pgwatch2 can be set up to work with Google Cloud SQL with very little change. Actually, using any other PostgreSQL variant should be equally simple. And it excels when compared to service provider instrumentation! In particular, it offers a lot more dashboards (roughly 30) to cover all potential problem areas. Additionally, it makes it simple to define new unique metrics through SQL! Hence, they might have a business background. Therefore, you can have some nice sales counters alongside your important database metrics.
About Enteros
Enteros offers a patented database performance management SaaS platform. It proactively identifies root causes of complex business-impacting database scalability and performance issues across a growing number of clouds, RDBMS, NoSQL, and machine learning database platforms.
The views expressed on this blog are those of the author and do not necessarily reflect the opinions of Enteros Inc. This blog may contain links to the content of third-party sites. By providing such links, Enteros Inc. does not adopt, guarantee, approve, or endorse the information, views, or products available on such sites.
Are you interested in writing for Enteros’ Blog? Please send us a pitch!
RELATED POSTS
Enteros, Database Performance, and Generative AI in Cloud FinOps for the Education Sector
- 27 February 2025
- Database Performance Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Optimizing Pharmaceutical Operations with Enteros: Enhancing Database Performance and Efficiency with AIOps Platforms
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Enteros for Media & Entertainment: Database Performance, Cloud FinOps, and Observability in a High-Demand Industry
- 26 February 2025
- Database Performance Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Enhancing Enterprise Performance in Healthcare: RevOps Strategies and Observability Platforms for Optimized Operations
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…