Preamble
This year at the pgconf.eu conference, we showed a “cluster in a box” demo case. Many of you have asked how we built it, so we have provided a blog post with all the information.
The objective was to demonstrate Patroni’s resilience and self-healing abilities while also giving participants hands-on experience injecting failures into a high-availability cluster. Any visitor to our booth could attempt to bring the cluster down by cutting power to any node using the large, shiny red switches. Patroni worked perfectly, handled failover easily, and recovered automatically when we expected it to. Only a few instances of database corruption due to the lack of power loss protection on our consumer-level SSDs required manual intervention, and those instances were easily fixed by simply erasing the corrupted database and letting Patroni reinitialize it.
What is Patroni
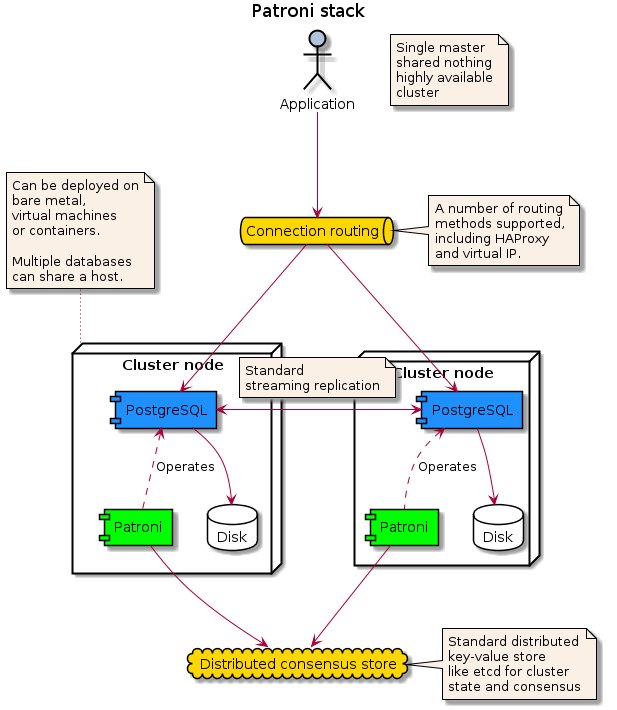
An open-source tool for creating highly available clusters is called Patroni. It’s better that it doesn’t solve all of your problems. Depending on factors such as the number of databases managed, whether they are running on hardware, virtual machines, or containers, network topology, durability vs. availability, and other factors, different businesses have very different preferences for what an ideal cluster architecture looks like. Patroni is an excellent foundation for a wide range of cluster topologies. In order to ensure that there is always one PostgreSQL master in the cluster but never more than one, it serves as the cluster manager. It delegated the challenging aspects of creating a HA cluster to tried-and-true tools, integrating them into a whole that is more than the sum of its parts.
The first difficult issue is replication. You need many copies of the database for high availability. Patroni utilizes PostgreSQL streaming replication for this. PostgreSQL streaming replication has proven to be quite dependable and quick, and it works well for us as the main component.
Getting cluster-wide consensus on the master node is the second challenging issue. It is solved by giving it to an outside, purpose-built tool that Patroni calls a “distributed consensus store.” The leader election, cluster state storage, and cluster-wide configuration are all handled by this consensus store. Supported providers include Etcd, Consul, Zookeeper, and Exhibitor. Soon, consensus will also be possible via the Kubernetes API. An external consensus store is a tried-and-true solution that lets the rest of the system know what it means. It also lets consensus nodes and data nodes be deployed separately.
Routing client connections to the current master node is the third outsourced issue. There are numerous different ways to accomplish this. DNS-based routing can be accomplished with Consul or related software. Patroni has an integration endpoint for TCP/IP load balancers that can be used with HAProxy, F5 BigIP, or AWS ELB. An IP address can be moved based on cluster state if the servers are on the same L2 network. As of PostgreSQL version 10, you can specify numerous hosts and let the client library choose the master server. You could also make your own by putting the Patroni health check API into your application’s connection management.
Deployment
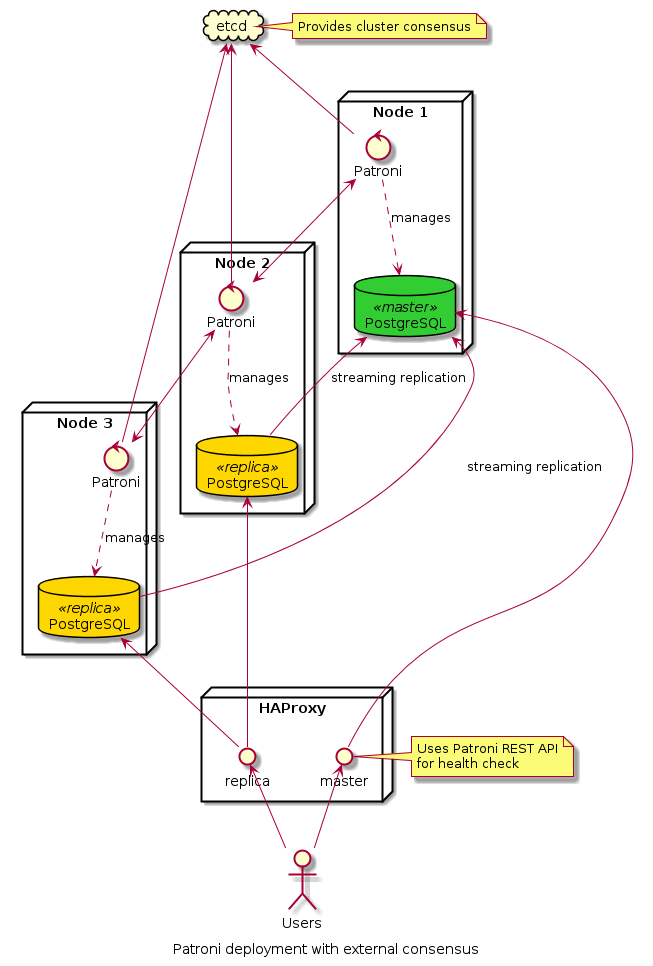
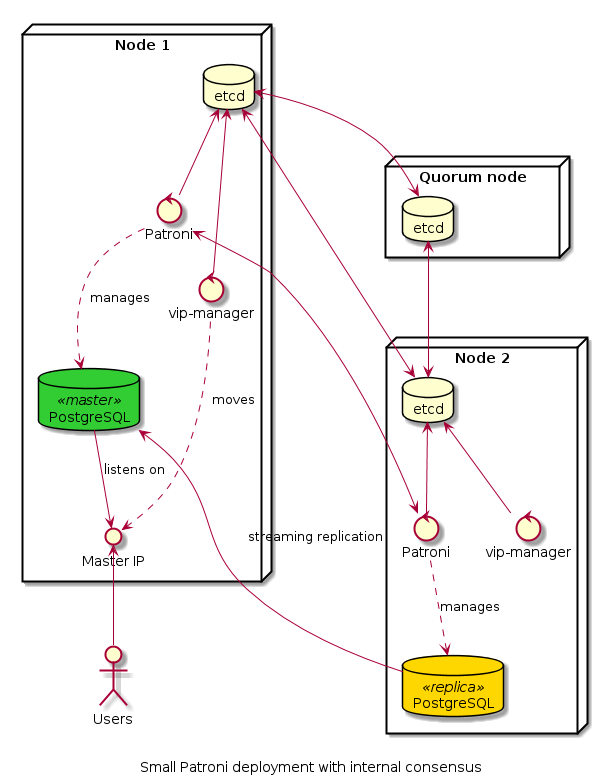
For the demonstration cluster, we chose a bare metal deployment with a separate etcd. When more than one node failed at the same time, the demonstrations were more interesting because of the external consensus. This configuration would be typical in situations where the company already uses etcd or where there are plans to use multiple database clusters. In this case, our etcd cluster was the head node laptop that ran a simple instance of etcd. A minimum of three etcd servers in separate failure domains with no single point of failure are required for real high-availability deployments. A HAProxy running on the same headnode handled client connection routing.
But because Patroni is so flexible, you can just install etcd on the database nodes if you only need a small database cluster that doesn’t need much maintenance. You still need 3 nodes because you can’t make a reliable HA cluster with less than that. The third node, however, can be a tiny virtual machine that only runs the etcd process. Just don’t put the VM on the same physical server as one of the databases; if you lose that server, your cluster will go into read-only mode.
The hardware
The hardware of our demo cluster included three Intel NUCs with Core i3 CPUs, 8 GB of memory, and a 256 GB SSD. Much more is required for this straightforward demo, but we expect bigger things from them.
A small plastic box called the “Failure Injection Unit” simply adds a nice, substantial toggle switch to the DC power coming from the power bricks that came with the NUCs. We could not help but also include large red toggle switch guards.
What Patroni does for you
Cluster nodes scramble to initialize the cluster as soon as they start up. One will be successful, launch initdb, and get the master lease. After obtaining a basic backup, other nodes will begin duplicating data from the master. Each node will check its local PostgreSQL database, and if it needs to, it will be restarted.
If the master node crashes or disconnects, its lease will end, and other nodes will wake up. They will work together to make sure that the node with the most transactions is the one that gets promoted. Other nodes will start replicating from that node after it receives the new master lease.
For the test cluster, we set the loop wait and retry timeout to 1 second, the master lease timeout to 5 seconds, and the HA proxy check and connect timeouts to 1 second. We got failover times of less than 10 seconds (measured from the last successful commit on a failed node to the next successful commit) with these pretty strict settings. Even though the default settings usually fail in less than 40 seconds, they are much less likely to be affected by short-term network problems. Most users are best served by these settings, given the relative likelihood of a node failing completely and the network being down for a short period of time.
The old master might have some unreplicated modifications that need to be backed out before rejoining the cluster if it comes back online. Patroni will automatically know when this is needed based on data from the past. It will then run pg rewind for you before reconnecting the node to the cluster.
By adjusting maximum lag on failover, master start timeout, and synchronous mode, you can choose how availability and durability are traded off. Standard PostgreSQL asynchronous replication settings are used by default, but failover is not allowed if the replica is more than 1MB behind. When synchronous mode is turned on, Patroni sets up PostgreSQL for synchronous replication, but it does not fail over automatically if transactions might be lost.
Integrations with backup systems can also be used to image fresh nodes. Start the cluster as a whole from a backup. Set aside a few nodes as special exceptions from failover. There is an option to turn on watchdog, which offers split-brain protection against bugs and operational faults, similar to what other solutions do with a much more complicated STONITH solution.
Overall, we have been very happy with the Patroni deployments we have made. It simply works, which is the best quality a piece of software can have.
About Enteros
Enteros offers a patented database performance management SaaS platform. It finds the root causes of complex database scalability and performance problems that affect business across a growing number of cloud, RDBMS, NoSQL, and machine learning database platforms.
The views expressed on this blog are those of the author and do not necessarily reflect the opinions of Enteros Inc. This blog may contain links to the content of third-party sites. By providing such links, Enteros Inc. does not adopt, guarantee, approve, or endorse the information, views, or products available on such sites.
Are you interested in writing for Enteros’ Blog? Please send us a pitch!
RELATED POSTS
Optimizing Real Estate Database Operations on Cloud Platforms with Enteros: Enhancing Performance, Cost Efficiency, and Scalability
- 31 January 2025
- Database Performance Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Optimizing Database Efficiency in the Banking World: How Enteros Leverages Cloud FinOps and Generative AI for Cost-Effective Performance
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Enhancing Healthcare Database Security and Performance with Enteros: AIOps-Powered Optimization
- 30 January 2025
- Database Performance Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Optimizing Biotech Operations with Enteros: Enhancing Database Performance, Cost Estimation, and RevOps Efficiency
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…