Preamble
Tables are used in relational databases to hold data in various formats. SQL Server stores data in a row and column manner, with each data type having its value. We establish integer, float, decimal, varchar, and bit data types while designing SQL tables. A table containing customer data, for example, might contain fields such as customer name, email, address, state, nation, and so on. On a SQL table, many SQL commands are executed, which can be classified into the following categories:
- These commands are used to build and change database objects in a database using the Data Definition Language (DDL).
- Creates new items.
- Objects are altered.
- Deletes things by dropping them.
- Truncate: This command removes all data from a table.
- These instructions insert, retrieve, change, remove, and update the database using the Data Manipulation Language (DML).
- Select: Data from a single or several tables is retrieved.
- Insert: This command adds new data to a table.
- Update: Makes changes to existing data.
- Delete: Removes records from a table.
- Data Control Language (DCL): These commands are linked to database rights and authorization controls.
- Grant: Gives user permissions.
- Revoke: Removes a user’s permissions.
- TCL stands for Transaction Control Language. These commands manage database transactions.
- Commit: The query’s changes are saved.
- Rollback: Reverts an explicit or implicit transaction to its start point or a savepoint within the trade.
- Transactions to be saved: Sets a transaction’s savepoint or marker.
Assume you have a SQL table containing customer order information. If you regularly insert data into this database, the table may grow to include millions of records, causing performance concerns in your applications. Index maintenance may take an extended period. Orders older than three years are frequently not required to be kept. You could delete the records from the table in these cases. This would free up storage space and cut down on maintenance time.
There are two techniques to remove data from a SQL table:
- Using a delete statement in SQL
- Using a truncate command
The differences between these SQL commands will be discussed later. Let’s start with the delete statement in SQL.
A SQL delete statement without any conditions
A SQL delete statement removes records from a table using data manipulation language (DML) instructions. You have the option of deleting a single row or all rows. There are no parameters required for an introductory delete statement.
Using the script below, let’s construct an Orders SQL table. [OrderID], [ProductName], and [ProductQuantity] are the three columns in this table.
Create Table Orders( OrderID int,ProductName varchar(50),ProductQuantity int)
(2,'XYZ',100),(3,'SQL book',50)
Fill in this table with a few records. Let’s say we wish to get rid of the table’s data. You can use the delete statement to remove data from a table by specifying the table name. Both SQL statements are identical. We can use the (optional) keyword to indicate the table name or select the table name straight after the deletion.
Delete OrdersGoDelete from OrdersGO
A SQL delete statement with filtered data
These SQL delete commands remove all data from the table. We don’t delete all of the rows from a SQL table in most cases. We can use a where clause with the delete statement to remove a specific record. The where clause specifies the filter criteria and, as a result, determines which rows should be removed.
Let us say we need to get rid of order id 1. When adding a where clause to a query, SQL Server checks the corresponding records and removes them.
Orders with orderid=1 should be deleted.
There are no rows removed if the where clause condition is false. We eliminated the ordered 1 from the orders database, for example. If we rerun it, the statement does not locate any rows to fulfill the where clause criteria. It yields 0 rows affected in this example.
SQL delete statement and TOP clause
The TOP statement can also be used to eliminate rows. The query below, for example, deletes the top 100 rows from the Orders table.
Delete top (100) [OrderID]from Orders
Because no ‘ORDER BY’ is supplied, it selects and deletes rows at random. The Order by clause can sort the data and eliminate the top rows. The query below sorts the [OrderID] column descending Order before deleting it from the [Orders] table.
Delete from Orders where [OrderID] In(Select top 100 [OrderID] FROM Ordersorder by [OrderID] Desc)
Rows are being deleted based on another table.
We occasionally need to delete rows based on data from another table. This table may or may not exist in the same database.
- Lookup a table
We can utilize the table lookup method, or a SQL join to delete these rows. For instance, we wish to remove rows from the [Orders] table that meets the following criteria:
The [dbo].[Customer] table should have equivalent rows.
Consider the following query, which includes a select statement in the delete statement’s where clause. SQL Server retrieves the entries that satisfy the select view before deleting them from the [Orders] table with the SQL delete command.
Delete Orders where orderid in(Select orderidfrom Customer)
- Joining SQL tables
lternatively, we can use SQL joins between these tables and remove the rows. In the below query, we join the tables [Orders]] with the [Customer] table. A SQL join always works on a common column between the tables. We have a column [OrderID] that join both tables together.
DELETE OrdersFROM Orders oINNER JOIN Customer c ON o.orderid=c.orderid
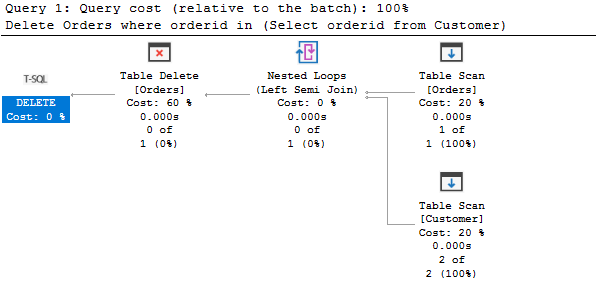
According to the execution plan, it runs a table scan on both tables, finds the matching data, and deletes it from the Orders table.
- Table expressions that are commonly used (CTE)
A common table expression (CTE) can also delete rows from a SQL table. First, we create a CTE to locate the record we want to delete.
The CTE is then joined to the SQL table Orders, and the records are deleted.
WITH cteOrders AS(SELECT OrderIDFROM CustomerWHERE CustomerID = 1 )DELETE OrdersFROM cteOrders spINNER JOIN dbo.Orders o ON o.orderid = sp.orderid;
Impacts on the identity range
In SQL Server, identity columns generate unique, sequential values for your column. They’re mainly utilized to make a row in a SQL table stand out. In SQL Server, a primary key column is also an excellent choice for a clustered index.
We have a [Employee] table in the script below. The identify column in this table is called id.
Create Table Employee(id int identity(1,1),[Name] varchar(50))
We created the identification values for the id column by inserting 50 records into this table.
Declare @id int=1While(@id<=50)BEGINInsert into Employee([Name]) values('Test'+CONVERT(VARCHAR,@ID))Set @id=@id+1END
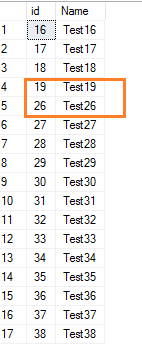
When we delete a few rows from a SQL table, the following values’ identity values are not reset. Let’s say you want to get rid of a few rows with identical values of 20 to 25.
Delete from employeewhere id between 20 and 25
View the table records now.
Select * from employee where id>15It depicts the identity value range’s gap.
SQL delete statement and the transaction log
Each row deletion in the transaction log is logged via SQL delete. Consider the following scenario: you need to delete millions of records from a SQL table. You should avoid deleting many entries in a single transaction since your log file will grow enormously, and your database will become unavailable. It could take hours to revert a delete statement if you cancel a transaction in the middle of it.
You should permanently delete rows in little chunks and commit those chunks regularly in this instance. You can, for example, delete 10,000 rows at a time, save it, and move on to the next batch. The transaction log growth can be limited when SQL Server commits the chunk.
Best practices
- Before removing data, you should always make a backup.
- SQL Server employs implicit transactions by default and commits records without prompting the user. Begin Transaction should initiate an explicit transaction as a best practice. It provides you with the ability to achieve or roll back a transaction. If the system is in incomplete recovery mode, you should also take frequent Transaction log backups.
- To avoid excessive transaction log usage, you should delete data in small bits. It also prevents additional SQL transactions from being blocked.
- Users should not be able to erase data if permissions are restricted. Only authorized users should be able to delete information from a SQL table.
- You wish to utilize a where clause in the delete statement. A SQL table’s filtered data is removed. If your application requires frequent data erasure, it’s a good idea to reset the identity values regularly. Otherwise, you may experience issues with identity value exhaustion.
- If you wish to empty the table, the truncate statement is the way to go. The truncate data statement eliminates all data from a database, requires little transaction logging, sets the notional identification value, and is faster than the SQL delete statement because it instantly deallocates all of the table’s pages.
- If your tables have foreign key constraints (parent-child relationships), delete the row first from a child table, then from the parent table. If you remove an item from the parent table, you may use the cascade on delete option to delete the entry from a child table. For further information, see the article Delete cascade and update torrent in SQL Server foreign key.
- When you delete rows with the top command, SQL Server deletes them randomly. Always utilize the principal clause in conjunction with the Order by and Group by clauses.
- A delete statement obtains an exclusive intent lock on the reference table, which means no other transactions can modify the data during that period. To read the data, use the NOLOCK hint.
- It’d be helpful if you could only utilize the table hint to override the default locking behavior of the SQL delete statement; experienced DBAs and developers should only use it.
Enteros
About Enteros
Enteros offers a patented database performance management SaaS platform. It proactively identifies root causes of complex business-impacting database scalability and performance issues across a growing number of RDBMS, NoSQL, and machine learning database platforms.
The views expressed on this blog are those of the author and do not necessarily reflect the opinions of Enteros Inc. This blog may contain links to the content of third-party sites. By providing such links, Enteros Inc. does not adopt, guarantee, approve, or endorse the information, views, or products available on such sites.
Are you interested in writing for Enteros’ Blog? Please send us a pitch!
RELATED POSTS
Optimizing Enterprise Performance in the Telecom Sector: How Enteros Drives Cloud FinOps Excellence
- 17 April 2025
- Database Performance Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Accelerating Performance Growth in the Insurance Sector with Enteros: Uniting Database Optimization and RevOps Efficiency
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Harnessing Enteros and Generative AI to Empower Database Administrators in the Hospitality Sector through a Scalable SaaS Platform
- 16 April 2025
- Database Performance Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Driving Cost Attribution and Performance Efficiency in the Travel Sector with AIOps and Cloud-Based Database Platforms
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…