SQL Server identity column
When inserting data, the SQL Server identity column populates a column with increasing numbers. Greg Larsen describes how it works in this article.
A column in a database table may need to configure with a different number for each entered record. An identification column may be a convenient way to populate a numeric column when a row inserts automatically. This article will explain what a SQL Server identity column is and how it works.
What is a SQL Server identity column?
An integer value assigns to a numeric column in the table when a record enters an identity column. Integer columns are commonly known as identity columns, but they can also write as bigint, smallint, tinyint, numeric, or decimal if the scale is 0. Cannot encrypt an identity column with an asymmetric key. However, it can use transparent Data Encryption to encrypt it (TDE). Furthermore, the definitions of an identity column must not allow for null values. One disadvantage of using an identity column is that each table can only have one.
Look into the sequence object if more than one numeric field per table needs to fill automatically, which is beyond the scope of this article.
The identity column’s seed and increment properties are automatically used to generate each new row value. When creating an identity column, use the following syntax:
|
1
|
IDENTITY [ (seed , increment) ]
|
The initial value entered into the table is a seed, and increment is added to the last identity value to create the next deal. If you want to override the defaults, you must supply both seed and increment values. The default values for seed and increment are one if no seed and increment values are specified.

Defining identity column using a CREATE TABLE statement
Most data architects will design the layout of a table. Such the identity column will be the first column in the table. In truth, this is just good practice, not a need for an identity column. An identity column can be any column in a table. However, each table can only have one identity column. Script 1 generates the Widget table, which includes an identification column.
Script 1: Adding an identification column to a table
The identity column, WidgetID, has a seed value of 1 and an increment value of 1. The
The seed value determines the identity value for the first row added to a table. The increment value determines the identity value of consecutive rows inserted into the table. The increment value adds to the current identity value for each row inserted after the initial row to determine the new row’s identity value. The current identity value is an integer for the identity column of the table’s most recent row. Run Script 2 to see how this works.
Script 2: Add three rows to the Table Widget and display the code.
Report 1 is displayed when the code in Script 2 runs.
Report 1 generates when Script 2 runs.

In Script 2, three rows add to the newly formed Widget table. Only the WidgetName and WidgetDesc columns received data from my script, but not the WidgetID column. Filled the WidgetID column for the first row with the seed provided in the CREATE TABLE statement, as seen in Script 1. By appending the increment value of 1 to the last identity value input, produce the WidgetID value 2 for the column with the WidgetName of doodad. By adding 1 to the identity value used on the second-row insert, the WidgetID number 3 for the row containing whatchamacallit acquire. Obtained WidgetName’s identity value.
It’s important to remember that the seed and increment values don’t have to be 1 and 1; they can be any value that fits the table. A table may, for example, utilize a seed value of 1000 and an increment of 10, as I did with the WidgetID column.
Script 3: Changing the seed and increment values
The NOTNULL property is not identified in the CREATETABLE statement for the ID column in Script 3, as it is for the identity column defined in Script 1. The not null column requirement can be omitted because the database engine will apply the NOTNULL property to any identification column produced behind the scenes. I’ll leave it to you to run the code in Script 3 and populate the DifferentSeedIncrement table with a few rows. You can see how the ID values created for each new row are entered into the DifferentSeedIncrement table and how SQL Server defines the table this way.
Uniqueness of an identity column
The existence of an identity column in a table does not imply that an identity value is unique. Because SQL Server allows identity values to be manually inserted and the seed value adjusted, identity column entries may not be exceptional. In a subsequent essay, I’ll go over the principles of introducing identity values and resetting the seed value. Must enforce uniqueness by utilizing a primary key, unique constraint, or unique index. As a result, one of the objects above must impose essence for each value in an identity column to ensure that it only includes unique values.
Identifying identity columns and their definitions in database
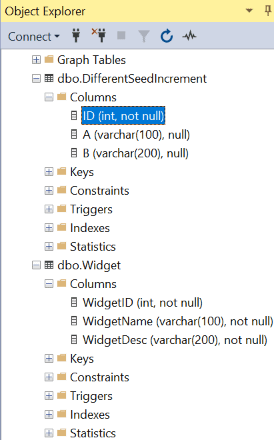
Can identify the identity columns and their meanings in a database in various ways. I cannot remember the identification column by presenting the columns in a table, as shown in Figure 1.
|
Figure 1 shows the column parameters for the tables created by Scripts 1 and 3.
To determine which column is an identity column, one must check the column’s attributes. Right-click on a column in ObjectExplorer and pick Properties from the drop-down context menu to examine its properties. Figure 2 shows the characteristics of the WidgetID column in the Widget table.
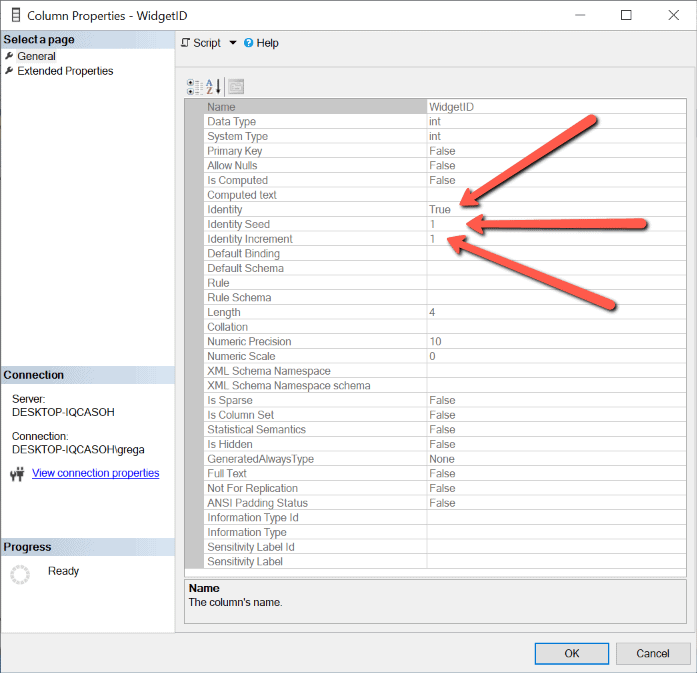
Figure 2: The dbo’s properties. Widget. Column WidgetId
If the Identity property sets to True, the column is an identity column. The seed and increment values are also displayed.
In a database with several tables, determine which columns are identity columns using the Object Explorer properties method. As seen in the TSQL code in Script 4, the sys. identity column view is another way to display all identity columns in a database.
Report 2: Output when script 4 is run

It’s worth noting that the last value field of the TableName of DifferentSeedIncrement is NULL. No new rows have been added to this table to change the LastValue.
Adding an identity column to an existing table
A current column cannot be converted to an identification column, but a new identity column can be added to an existing table. Run the code in Script 5 to see how this is performed. This script creates a new database, adds two rows, and then changes the table to add a new identity field.
Adding an identity column to Script 5
Report 3 displays the outcome of Script 5.
Report 3: Invoices Table Rows

The identity values for the new InvoiceID field were auto-populated on all existing rows when Report 3 was released.
Altering an existing table to define an identity column
As previously stated, SQL Server does not allow you to transform an existing column into an identity column using the ALTER TABLE/ALTER COLUMN command. There are, however, ways to turn a current table column into an identification column. The following example demonstrates how to utilize a work table to change an existing table’s column to an identity column.
The script utilizes the ALTER TABLE… SWITCH command to change an existing column to an identity column. The SWITCH option adds to the ALTER TABLE command in SQL Server 2005 as part of the partitioning capability. The TSQL code in Script 6 uses a temporary work table and the SWITCH option to facilitate changing an existing column to an identity column.
Script 6: Adding an identification column to an existing column
Script 6 followed four steps to transform an existing column into an identification column. When using this method to add an identity column to a current table, keep the following points in mind:
To use the SWITCH option on the ALTERTABLE statement, the original table’s column transformed to an identity column must not allow nulls. The switch operations will fail if it accepts null.
Use the DBCCCHECKIDENT command to reseed the identity column of the new table. If this does, the original seed value will use for the next row entered, resulting in duplicate identity values if the identity column doesn’t contain a primary key, unique constraint, or index.
Before issuing the ALTER TABLE…All foreign keys must eliminate when using the SWITCH command.
The temporary table would require the same indexes if the original table had indexes. Otherwise, the switch operation will fail.
There must be no transactions against the table during the ALTER TABLE…The SWITCH operation is running.
While the transition is ongoing, no new deals will be permitted to begin. They may lose security rights while shifting tables because they link to the target table. As a result, before or shortly after the switch action, ensure that the original table’s rights reproduce on the target table.
Reseeding an identity column
Using the DBCC CHECKIDENT command, I reseeded the identity column value in the preceding example.Reseeding an identity column value is also necessary when incorrectly inserting multiple rows to a table or deleting erroneous rows. The existing identification strengthens for each row added while inserting rows incorrectly. As a result, once all defective rows eliminate, the next row will use the next identity value, creating a considerable gap. If this error has occurred, reseeding the identity value will ensure no large gap of missing identity data. In the previous example, I reseeded the identity column value by using the
Use the DBCC CHECKIDENT command to replant an identification value for a table. The table name argument indicates the table’s name that contains the identity definition. If the table does not have an identity column, the DBCC CHECKINDENT command will fail. If no other settings are specified, the current identity value will reset to the highest value found in the existing identity column. The NORESEED option indicates that it will not change the seed value. You can use this option to determine your current and maximum identity values. Should reseed the identity value if the current and maximum values differ.
Can use the RESEED option to reset the current identity value if it is less than the maximum or if there is a big gap between the identity values. With or without a new reseed value, can use the RESEED option. Will update the core identity value to the maximum value returned in the identification column of the database supplied if no new reseed value is specified.
Script 6 explains how to use the DBCCCHECKINDENT command to reseed an identity column value without utilizing the RESEED option. In script seven, the RESEED option in the TSQL code uses to set the current seed value to 2.
Using the RESEED option in Script 7
When utilizing the RESEED option with a new seed value, be cautious. What matters is the new seed use. SQL Server doesn’t care. The latest source set may produce duplicate identity values that are less than the table’s maximum seed value.
The SQL Server identity column
When a new row adds to a table, an identity column will automatically generate and populate a numeric column value. The identity column generates a unique identity value for each row inserted by combining the current seed value with an increment value. This tutorial just covered the basics of working with the identification column.
About Enteros
IT organizations routinely spend days and weeks troubleshooting production database performance issues across multitudes of critical business systems. Fast and reliable resolution of database performance problems by Enteros enables businesses to generate and save millions of direct revenue, minimize waste of employees’ productivity, reduce the number of licenses, servers, and cloud resources and maximize the productivity of the application, database, and IT operations teams.
The views expressed on this blog are those of the author and do not necessarily reflect the opinions of Enteros Inc. This blog may contain links to the content of third-party sites. By providing such links, Enteros Inc. does not adopt, guarantee, approve, or endorse the information, views, or products available on such sites.
Are you interested in writing for Enteros’ Blog? Please send us a pitch!
RELATED POSTS
Optimizing Database Performance with Enteros: Revolutionizing Cloud FinOps in the Technology Sector
- 23 January 2025
- Database Performance Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Enteros: Streamlining Billing Responsibility and RevOps for Enhanced Database Performance in the Healthcare Sector
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Maximizing Database Performance with Enteros: Empowering the Financial Sector Through Cloud FinOps and RevOps
- 22 January 2025
- Database Performance Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Enteros: Harnessing Forecasting and Observability with AIOps for Cost Optimization in the Real Estate Sector
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…