Kubernetes: Challenges for observability platforms
Kubernetes is the contra standard for containerized applications. It addresses several challenges, including workload distribution among servers, fault tolerance, and job rescheduling in the event of a failure. While the underlying abstraction and automation make life easier for Kubernetes operators by speeding up development processes and lowering complexity, the inherent abstraction and automation can lead to new forms of failures that are difficult to discover, diagnose, and prevent.
Kubernetes monitoring is typically managed using a separate dashboard. It displays the cluster’s status and alerts when anomalies arise. Monitoring agents installed on Kubernetes nodes keep an eye on the Kubernetes environment. They also provide helpful information on the node state. However, linked components and processes in your Kubernetes architecture, such as virtualization infrastructure and storage systems (see image below), can cause issues.
As part of a more comprehensive monitoring solution, Kubernetes Dashboard can be used. The fundamental building components to consider while constructing your Kubernetes monitoring solution are introduced in this post. As a platform operator, you want to immediately identify issues and learn from them to avoid future disruptions. You want to test your code as an application developer to examine how your services interact and where bottlenecks cause performance degradation. Monitoring software may analyze and report such information, provide deep insights and conduct automated actions based on those insights.

The Kubernetes experience
Creating a new cluster is straightforward when using managed environments. A web server is up and running in minutes after applying the first manifests. They most likely copy and paste from a how-to tutorial.
However, when you gain experience and increase the setup for production, you may find that:
- Your application isn’t quite as stateless as you assumed.
- It’s more challenging to set up storage in Kubernetes than using a file system on your host.
- It’s possible that keeping configurations or secrets in the container image isn’t the most excellent choice.
You overcome all of these challenges, and your application runs properly after some time. Formed some assumptions about the operating circumstances during the adoption phase, and the application deployment is based on them. Even though Kubernetes includes built-in error/fault detection and recovery methods, unanticipated anomalies can still occur, resulting in data loss, instability, and a terrible user experience. Furthermore, if your resource constraints are set too high, Kubernetes’ auto-scaling approaches can hurt expenses.
You should instrument your application to provide comprehensive monitoring insights to protect yourself against this. It allows you to respond (automatically or manually) to anomalies and performance concerns that affect the end-user experience.
What does observability mean for Kubernetes?
Kubernetes appears to solve all of your demands for creating and executing contemporary, scalable, and distributed applications. Nonetheless, Kubernetes, as a container orchestration technology, does not know the internal status of your apps. That’s why developers and SREs use telemetry data (such as metrics, traces, and logs) to better understand their code’s behavior during runtime.
- Metrics are numerical representations of time intervals. They can assist you in determining how a system’s behavior varies over time (for example, how long do requests take in the current version versus the previous version?).
- Traces on a distributed system reflect causally associated distributed events, such as how a request travels from the user to the database.
- Logs are simple to create and can contain data in plain text, structured (JSON, XML), or binary formats. Event data can also be represented using logs.
- Aside from the three pillars of observability (logging, metrics, and traces), more advanced systems can include topology, real-world user experience, and other meta-data.
Monitoring makes sense of observability data
To make sense of the deluge of telemetry data supplied by observability, a system for storing, baselining, and analyzing it is necessary. Such analysis must deliver actionable solutions based on acquired data with anomalous root-cause detection and automated repair actions. Various monitoring products are available, each with its own set of features, alerting mechanisms, and integrations. Some of these monitoring programs use a declarative approach, which requires precise specifications of the hosts and services. Others are almost self-configuring; they detect entities to be monitored automatically, or the monitored entities register themselves when the monitoring agent is deployed.
A layered approach for monitoring Kubernetes
“The IaaS layer Kubernetes operates on is only as good as the IaaS layer it runs on.” Kubernetes, like Linux, has reached the distro era.” – (Kelsey Hightower via Twitter, 2020)
Even if a Kubernetes system runs flawlessly on its own, with no issues detected by your monitoring tool, you may encounter dangerous faults outside of Kubernetes.
Example:
Virtual machines run inside dynamically provisioned virtual machine image files in your Kubernetes deployment (best practice or not). You haven’t noticed that the virtualization host is running out of disk space (or shared storage). When the machine image tries to scale up, your hypervisor shuts down the virtual machine, rendering one of your nodes unusable.
The error was not detected by either the Kubernetes monitoring or the OS agent installed on the Kubernetes node in this case. Given the prevalence of such cross-cutting irregularities, we should consider a more comprehensive approach to Kubernetes monitoring. A solution like this can be divided into smaller, more concentrated sections, as shown below.
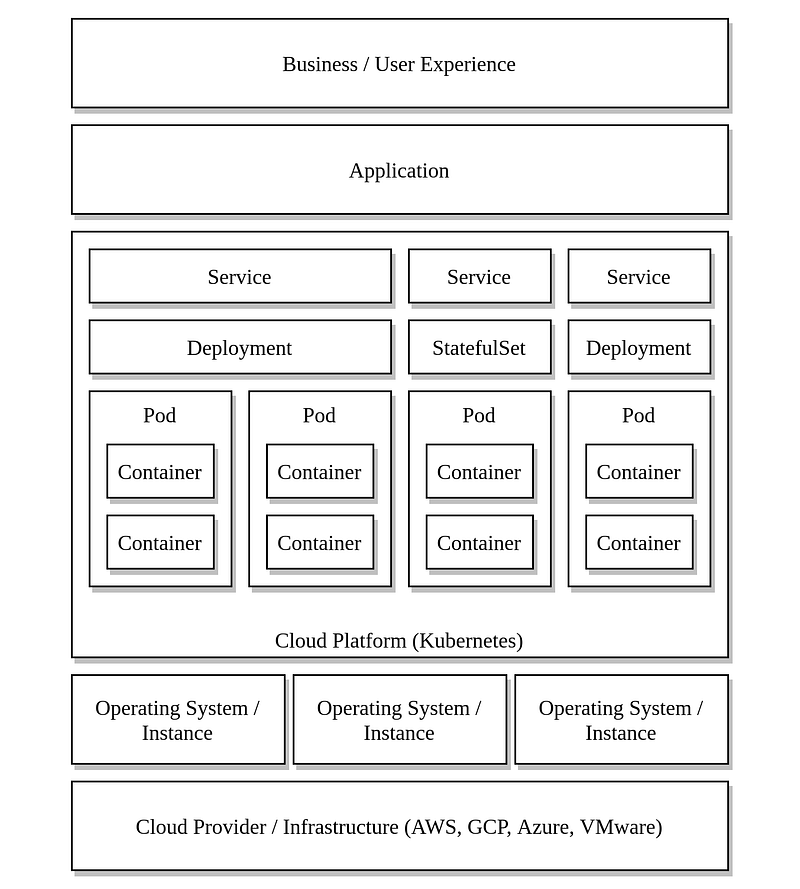
Kubernetes Monitoring Solution Layers Let’s look at each layer one by one.
Cloud provider/infrastructure layer
Depending on the deployment style, problems can arise in your cloud provider’s infrastructure or your on-premise environment. While using a cloud service, you want to make sure you don’t run out of resources while also not consuming more than your Kubernetes cluster will demand as it develops. As a result, maintaining track of the quotas set up on the cloud provider and monitoring the utilization and expenses of the resources you consume will help you cut costs while ensuring that you don’t run out of resources. Additionally, changes in the cloud infrastructure can cause issues. Therefore, audit records can immediately become exporters or importers into a monitoring system.
When running your Kubernetes environment on-premises, you must keep track of all infrastructure components that may have an impact. Some examples are network (switches, routers), storage (mainly when using thin provisioning), and virtualization infrastructure. These standard network metrics are throughput, error rates on network interfaces, and even dropped/blocked packets on security devices. You can use log file analysis to detect problems (such as over-provisioning) before they happen.
Operating system / Instance layer
You are responsible for keeping your operating system up to date and maintained if you do not run your Kubernetes cluster on a managed service. When doing so, it’s a good idea to double-check the health of your Kubernetes services and the container runtime. Checking for security updates/patches and automatically installing them during the next update cycle should also be on your list. Even at this tier, log entries can help you determine if something is wrong with your system and are a good source for system audits.
Cloud platform layer
You assured that the infrastructure of your Kubernetes environment is reliable and observable by building the bottom layers of your monitoring solution. Many Kubernetes issues arise due to apparent misconfigurations or as the cluster’s number of apps expands without the infrastructure expands.
You can check if all nodes in your cluster are schedulable, as explained in many guides (for example, kubectl get nodes). Can use pods, deployments, and any other Kubernetes object type in the same way. You may see that certain Pods are “PENDING” as you continue to provide additional onboard services to your cluster. It implies that the scheduler is unable to complete its task. Using kubectl describe kind> object> will give more information and print the events associated with this object. This information is frequently helpful and gives you an idea of what you lack.
As with any other clustered system, keep in mind that a node can fail on purpose or by accident. In this instance, you’ll want to be able to schedule workloads on the remaining nodes, so keep that in mind when defining threshold levels on your monitoring infrastructure.
You may configure a deployment only to discover that it will create no pods. A diverging value of desired and available pods of deployment is one sign that something is wrong (kubectl gets deployment). Finally, while specifying low memory requests, your pods may repeatedly restart due to running out of memory. Can quickly remedy it by adjusting container requests and restrictions.
Application layer
Even if your infrastructure is flawless and Kubernetes is error-free, you may still encounter issues at the application layer. Example: You’re operating a multi-tier application (web server, database). You’ve set up an HTTP health check on the application server that prints out “OK” and another on the database that does a simple database query. Both health checks are functioning normally, and there appears to be no issue. When consumers want to do a specific action via the web interface, they present with a blank page that continues to load indefinitely.
In the preceding example, the application bug does not cause the system to crash and cannot identify using simple check procedures. You can, however, instrument your application to identify such anomalies, as discussed in one of the earlier sections. Requests send to the application server and the database query, but no answer is received, for example, according to traces. May queue new submissions on the application after some time, and the connection pool may become whole. The HTTP Server may stop receiving requests, and the health check will fail.
Customer activity is replicated using synthetic monitoring techniques, allowing the availability from a customer’s perspective to be evaluated. In the case of the previous example, it can build up a check to replicate this behavior, and it will signal an error if the request is not complete. Real-time user monitoring provides information about how your users interact with your app. RUM not only helps you uncover faults but also usability concerns, such as a high number of users abandoning your site at a given moment in the purchase process.
Business layer
If a consumer cannot use or dislike a new feature, it may fail. As a result, linking modifications or new features in your app to business-related KPIs like revenue or conversion rate might assist you in quantifying the benefits of your software development efforts. For example, can use tags and metrics to identify a new version of an application compared to the prior version. If you notice a negative influence on these measures, reverting to the previous successful version is a viable alternative.
Possible solutions
Various products can help you with your Kubernetes monitoring journey. If you prefer open-source software, there are multiple CNCF projects, such as Prometheus, can use that to store and scrape monitoring data. In addition, OpenTelemetry aids in the development of instrumentation software, and Jaeger uses it to visualize tracing data. Other projects, including Zabbix and Icinga, can assist you in maintaining and monitoring your services and infrastructure. Grafana is a data visualization tool that may use to depict data collected by nearly any monitoring instrument.
Many open-source tools focus on specific use cases, whereas commercial solutions typically cover a more comprehensive range of infrastructure, application, and real-user monitoring scenarios. Take a look at these four blog posts if you want to learn more about Kubernetes monitoring features:
- With operational insights into Kubernetes pods, you can improve application and infrastructure observability.
- Day 2 operations monitoring of Kubernetes infrastructure
- On Google Kubernetes Engine AWS EKS, self-upgrading observability takes 60 seconds.
- Monitoring is now available as a self-service option.
Conclusion
There appears to be a lot to consider when designing a Kubernetes monitoring solution that isn’t tied to Kubernetes. By breaking down monitoring into smaller chunks, teams may focus on and maintain their areas of responsibility. For example, application deployments can move from on-premises to public cloud infrastructure without impacting application monitoring. Kubernetes is a dynamic orchestration platform with application instances that come and go in seconds. A monitoring solution that can handle this behavior ensures a more pleasant monitoring experience.
Numerous techniques and resources are available to assist you in your monitoring endeavors. Commercial observability technologies allow you to monitor your Kubernetes infrastructure comprehensively with minimal setup work. Keeping these considerations in mind as you build your Kubernetes monitoring solution will help you keep your clients happy and your systems stable.
About Enteros
IT organizations routinely spend days and weeks troubleshooting production database performance issues across multitudes of critical business systems. Fast and reliable resolution of database performance problems by Enteros enables businesses to generate and save millions of direct revenue, minimize waste of employees’ productivity, reduce the number of licenses, servers, and cloud resources and maximize the productivity of the application, database, and IT operations teams.
The views expressed on this blog are those of the author and do not necessarily reflect the opinions of Enteros Inc. This blog may contain links to the content of third-party sites. By providing such links, Enteros Inc. does not adopt, guarantee, approve, or endorse the information, views, or products available on such sites.
Are you interested in writing for Enteros’ Blog? Please send us a pitch!
RELATED POSTS
Optimizing Enterprise Performance in the Telecom Sector: How Enteros Drives Cloud FinOps Excellence
- 17 April 2025
- Database Performance Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Accelerating Performance Growth in the Insurance Sector with Enteros: Uniting Database Optimization and RevOps Efficiency
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Harnessing Enteros and Generative AI to Empower Database Administrators in the Hospitality Sector through a Scalable SaaS Platform
- 16 April 2025
- Database Performance Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Driving Cost Attribution and Performance Efficiency in the Travel Sector with AIOps and Cloud-Based Database Platforms
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…