Preamble
Many mission-critical enterprise applications rely on Oracle Database. Using Amazon Web Services (AWS) for such applications has several advantages, including agility, flexibility, and reliability.
However, teams in charge of transferring Oracle Databases frequently have a genuine concern: will they be able to attain the same level of database performance as they do in their present on-premises environments?
A slow back-end database slows down the apps, no matter how much power or horizontal scaling the servers supply. Because backed databases are so important, they’re usually operated on the fastest (and most expensive) hardware available: massive servers, all-flash storage arrays, Oracle Exadata-designed systems, or even mainframes.
Is it possible for AWS to match the performance of such on-premises systems? In most circumstances, the short response is yes. Also, the Elastic Compute Service provides a wide range of high-performance server, network, and storage options that match or outperform most on-premises systems.
Of course, the most difficult circumstances necessitate a more thorough analysis and possibly more complex arrangements. Meanwhile, the most straightforward configurations can now attain higher performance levels thanks to the new Amazon Elastic Block Store (EBS) and EC2 features.
When it comes to helping Oracle Database customers migrate to AWS, we’ve found that simple and inexpensive solutions yield the best results. In this post, I’ll look at how the new Amazon EBS gp3 general purpose volumes and Amazon EC2 R5b instances help Oracle Databases run faster.
FlashGrid is an AWS ISV Partner that allows you to run Oracle RAC databases in clusters on AWS. Also, it offers multi-Availability Zone (AZ) support, complete control over database software, infrastructure as code (IaC) deployment approach, and 24-hour support.
Why Storage Performance Matters
It’s crucial to remember that a database system’s principal function is to write and retrieve data. The amount of work required can be substantial, yet data retrieval does not always necessitate access to persistent storage. On the other hand, rapid access to storage is crucial for fast database performance in many circumstances.
What criteria do we use to evaluate storage performance? In the vast majority of real-world cases, the following measurements are sufficient:
- Small block (e.g., 8KB) read i/o operations per second (IOPS).
- Write IOPS: Small block write i/o operations per second (e.g., 8KB).
- MBPS (Megabits Per Second): The amount of data read per second in large chunks (e.g., 1MB).
- MBPS (Megabits Per Second): The amount of data written per second in large blocks (e.g., 1MB).
- Read Latency: The time it takes to read a small data block (for example, 8KB).
- Write Latency: The time it takes to write a small data block (e.g., 8KB).
These metrics are familiar to most database administrators and system developers. But, when migrating Oracle databases to AWS, which ones should, we prioritize?
In FlashGrid’s four years of transferring Oracle databases to AWS, we’ve noticed a distinct pattern of where bottlenecks typically occur and where they don’t. The actual jams are frequently not the same as those our customers are initially concerned about.
Even with a write-heavy OLTP application and even a multi-AZ cluster, writing IOPS and writing latency are rarely a concern. Write MBPS are helpful for loading or restoring extensive databases; however, they are seldom needed if Read MBPS suffice.
Meanwhile, read latency is critical, but SSD-based EBS volumes are never an issue if IOPS and MBPS aren’t saturating. Also, it leads us to the most common storage-related suspects in a database that isn’t operating well: IOPS and MBPS are two terms that are used interchangeably.
If User I/O is at the top of the Wait Classes by Total Wait Time list in your Oracle AWR report, the bottleneck is likely caused by a lack of Reading IOPS and Read MBPS. Even if you’re using 50 percent of the available throughput, you should expect some sluggishness.
Also, if the Avg Wait for “DB file sequential read” / “DB file dispersed read” / “direct path read” events is significantly longer than 1ms, Read IOPS and Read MBPS are approaching saturation. It can happen at an even lower average throughput utilization if your workload is bursty.
In other words, if your Read IOPS or Read MBPS are too low, your database will suffer. On the other hand, AWS does not size Read and Write throughput individually. We only need to look at the total number of IOPS and MBPS accessible in your data disk groups.

How the New R5b Instance Type Helps
Let’s observe that the R5 instance family has been the most popular for operating Oracle databases on Amazon EC2. The explanation is that the memory-to-CPU size ratio is optimal (in most circumstances).
The new R5b series now has the exact dimensions as the R5, but with a storage throughput that is more than three times higher.
|
R5
|
R5b
|
|
|
Storage Read/Write IOPS (max)
|
80,000 IOPS
|
260,000 IOPS
|
|
Storage Read/Write MBPS (max)
|
2,375 MB/s
|
7,500 MB/s
|
The conclusion is straightforward: if your database’s performance has been hampered by storage throughput, R5b instances can help. Also, suppose a more sophisticated design was necessary to achieve the desired performance. In that situation, instead of using local SSDs or a large number of storage nodes, you might be able to finish it more straightforwardly by using EBS.
How the New gp3 EBS Volume Type Helps
Let’s look at how we may configure our Amazon EBS volumes to reach the 260,000 IOPS and 7,500 MBPS offered by the most popular R5b instances.
We must first decide whether to employ Provisioned IOPS SSD volumes or General Purpose SSD volumes. SSD volumes with Provisioned IOPS provide more IOPS per volume. On the other hand, Oracle ASM makes it simple to join several books per disk group and take advantage of their combined throughput.
Each gp3 volume can have up to 16,000 IOPS and 1,000 MBPS of throughput. As a result, we hit the 260,000 IOPS cap for the most prominent R5b instances using 17 gp3 volumes.
We’ll need eight gp3 volumes to attain the maximum instance speed of 7,500 MBPS. We’d have to utilize 4x more books with gp2 to get the same MBPS because gp2 only allows 250 MBPS per volume.
It’s also worth noting that, unlike gp2, gp3 volumes allow us to configure IOPS and MBPS regardless of volume capacity. gp2 has the same maximum IOPS per volume as gp1, but the IOPS to capacity ratio is three IOPS/GB. If we wanted more IOPS with gp2, we could overprovision capacity (and pay for it). With gp3, there’s no need for this.
“Why not utilize io2 volumes that allow you to configure IOPS regardless of capacity?” you might wonder. Let’s have a look at how much each volume kind would cost.
The expenses are for three distinct capacity/performance combinations in the US East (North Virginia).
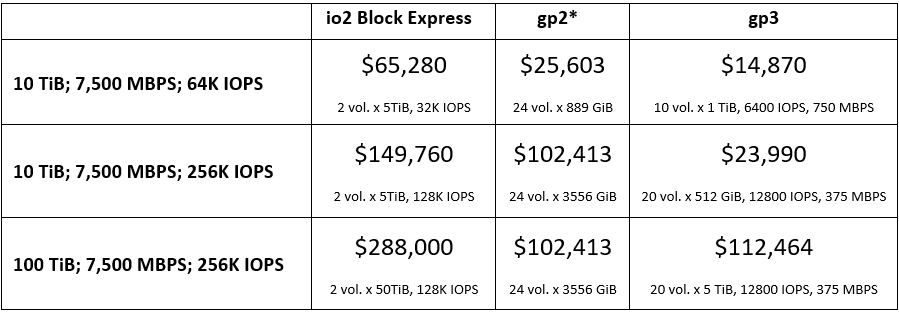
* Because of the 250 MBPS limits per volume and the number of books per EC2 instance, all gp2 setups have a realistic maximum of 6,000 MBPS.
We chose io2 Block Express over io2 because of its superior performance and lower cost. When comparing gp3 to io2 Block Express, gp3 comes out on top in price while providing the same total MBPS and IOPS.
When gp3 is compared to gp2, gp3 comes out on top in configurations with smaller capacities since gp2 requires an excessive quantity of unused capacity. Even if we increase the number of volumes per instance to the highest allowable limit, we can’t reach the 7,500 MBPS using gp2 because the MBPS per volume is 4x lower.
Let’s also be clear about the EBS volumes’ durability. The io2 volumes have a higher 99.999 percent durability than the gp3 volumes, 99.98-99.99 percent durability. However, we use two- or three-way data mirroring in FlashGrid clusters at the ASM disk group level.
In multi-AZ deployments, mirroring compensates for the lower durability of gp3 volumes compared to io2, and it also adds protection against a local disaster affecting one Availability Zone. Mirrored gp3 drives are therefore ideal for mission-critical Oracle databases.

Multiplying Storage Throughput with Multiple Nodes
The per-instance IOPS and MBPS are multiplied even more by joining numerous nodes in a cluster. Two and three database nodes with EBS volumes directly attached are the most common FlashGrid cluster setups.
The FlashGrid Read-Local technology allows you to take advantage of the entire read IOPS and read MBPS across two or three nodes.
In a FlashGrid cluster, the maximum theoretical EBS read throughput is:
- 520K IOPS and 15,000 MBPS on two RAC nodes
- 780K IOPS and 22,500 MBPS on three RAC nodes
Measuring Storage Throughput
Let’s look at the actual storage throughput through the database stack. Also, the simplest way to do this is to use the SQL code below to invoke the Oracle database’s DBMS RESOURCE MANAGER.CALIBRATE IO procedure:
SET SERVEROUTPUT ON; DECLARE lat INTEGER; iops INTEGER; mbps INTEGER; BEGIN DBMS_RESOURCE_MANAGER.CALIBRATE_IO (<number of disks>, <max latency>, iops, mbps, lat); DBMS_OUTPUT.PUT_LINE ('Max_IOPS = ' || iops); DBMS_OUTPUT.PUT_LINE ('Latency = ' || lat); DBMS_OUTPUT.PUT_LINE ('Max_MBPS = ' || mbps); end; /In the SQL code, the following parameters are used:
The total number of disks in the disk group utilized for database files is the number of disks>.
max latency> – the maximum permitted latency in milliseconds, such as ten milliseconds.
With r5b.24xlarge database nodes and (20) gp3 volumes per database node-set with 16,000 IOPS and 1000 MBPS each, we measured the following results at FlashGrid:
|
Cluster configuration
|
Max IOPS
|
Latency (ms)
|
Max MBPS
|
|
2 RAC database nodes
|
456,886
|
0.424
|
14,631
|
|
3 RAC database nodes
|
672,931
|
0.424
|
21,934
|
The most significant IOPS is 87 percent of the theoretical maximum, while the maximum MBPS is >97 percent. These results show that the storage functions are as expected and that the software stack can utilize the storage’s capabilities.
Deploy a Cluster to See it Working
You can set up a FlashGrid cluster with Oracle RAC in less than two hours. Also, Oracle software installation is included in the deployment, which is done using an AWS CloudFormation template.
Follow the deployment guide’s instructions and make the following choices:
- On the Source node tab in FlashGrid Launcher, please choose one of its R5b example sizes for database nodes.
- Ensure the number of disks, IOPS, and MBPS for each disk is configured in the DATA disk group on the Storage tab in FlashGrid Launcher so that the overall total throughput meets the throughput of the selected example size.
Following typical Oracle methods, you can establish or restore an existing database from backup after deploying a cluster.
Real-World Use Case
A sportswear company is one of FlashGrid’s customers, and its Oracle eCommerce system is hosted on AWS in a three-node RAC cluster. The merchant had a record number of purchases from their online store during the 2020 holiday season. As a result, the peak storage throughput use began to exceed 50% of the capacity of their r5.12xlarge instances and gp2 volumes.
It has become a clear challenge for the 2021 Christmas season, which is predicted to be busier.
Simply raising gp2 storage and instance sizes to r5.24xlarge might provide sufficient storage throughput, but it would also double Amazon EC2 and EBS charges and leave the extra CPU and memory resources underused.
Just in time, the new r5b instance type arrived. The customer treble storage throughput while maintaining nearly the exact overall cost by switching from r5.12xlarge to r5b.12xlarge and from gp2 to gp3 volumes.
Summary
The performance of the underlying storage frequently influences the performance of Oracle databases.
Without introducing any more complexity, the new Amazon EC2 R5b instance type allows you to achieve 3x higher storage throughput. Meanwhile, the new Amazon EBS gp3 volume type provides maximum throughput at a very cheap cost.
In a FlashGrid-engineered cloud system, combining clustered R5b instances with several gp3 volumes per instance dramatically improves the possibilities for establishing high-performance databases on AWS and migrating from current high-end on-premises systems.
About Enteros
Enteros offers a patented database performance management SaaS platform. It proactively identifies root causes of complex business-impacting database scalability and performance issues across a growing number of RDBMS, NoSQL, and machine learning database platforms.
The views expressed on this blog are those of the author and do not necessarily reflect the opinions of Enteros Inc. This blog may contain links to the content of third-party sites. By providing such links, Enteros Inc. does not adopt, guarantee, approve, or endorse the information, views, or products available on such sites.
Are you interested in writing for Enteros’ Blog? Please send us a pitch!
RELATED POSTS
Revolutionizing Healthcare IT: Leveraging Enteros, FinOps, and DevOps Tools for Superior Database Software Management
- 21 November 2024
- Database Performance Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Optimizing Real Estate Operations with Enteros: Harnessing Azure Resource Groups and Advanced Database Software
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Revolutionizing Real Estate: Enhancing Database Performance and Cost Efficiency with Enteros and Cloud FinOps
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Enteros in Education: Leveraging AIOps for Advanced Anomaly Management and Optimized Learning Environments
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…