Preamble

There are many PostgreSQL manuals on the network that describe the basic commands. But as you dive deeper into the work, you’ll encounter practical issues that require advanced commands.
Such commands, or snippets, are rarely described in the documentation. Let’s look at a few examples, useful both for developers and for database administrators.
Getting information about a database
Database size
To get the physical size of the database files (storage), we use the following query:
SELECT pg_database_size(current_database());
The result will be presented as a number of the kind 41809016.
current_database() is the function that returns the name of the current database. The name of the current database may be entered in the text instead:
SELECT pg_database_size('my_database');
To get the information in a human-readable form, use the function pg_size_pretty:
SELECT pg_size_pretty(pg_database_size(current_database()));
As a result, we get information like 40 Mb.
Table list
Sometimes a list of database tables is required. For this purpose, we use the following query:
SELECT table_name FROM information_schema.tables
WHERE table_schema NOT IN ('information_schema', 'pg_catalog');
information_schema is a standard database schema that contains collections of views, such as tables, fields, etc. The table views contain information about all database tables.
The query described below shall select all tables from the specified database schema of the current database:
SELECT table_name FROM information_schema.tables.
WHERE table_schema NOT IN ('information_schema', 'pg_catalog')
AND table_schema IN('public', 'myschema');
In the last condition IN, you can specify the name of a particular scheme.
Table size
By analogy with obtaining the database size, the table size can be calculated using the corresponding function:
SELECT pg_relation_size('accounts');
The pg_relation_size function returns the size that occupies the specified layer of a given table or index on the disk.
Name of the largest table
To display the list of tables in the current database sorted by the table size, perform the following query:
SELECT relname, relpages FROM pg_class ORDER BY relpages DESC;
In order to display the information about the largest table, limit the query to LIMIT:
SELECT relname, relpages FROM pg_class ORDER BY relpages DESC LIMIT 1;
- relname is the name of a table, index, view, etc.
- relpages – the size of this table view on disk in the number of pages (by default, one page is equal to 8 Kb).
- pg_class – the system table that contains information about the database table links.
List of connected users
To find out the name, IP and port used by the connected users, we will make the following request:
SELECT datname,usename,client_addr,client_port FROM pg_stat_activity;
User activity
To find out the connection activity of a particular user, we use the following query:
SELECT datname FROM pg_stat_activity WHERE usename = 'devuser';
Working with data and table fields
Deletion of identical rows
If it so happens that there is no primary key in the table, you will probably find duplicates among the records. If you need to set a constraint for such a table, especially a large one, to check its integrity, then we will delete the following elements:
- duplicated rows,
- situations when one or more columns are duplicated (if these columns are supposed to be used as the primary key).
Let’s look at a table with customer data, where an entire row (the second in the row) is duplicated.
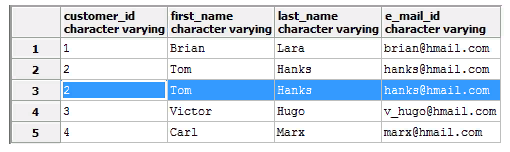
The following query will help you remove all duplicates:
DELETE FROM customers WHERE ctid NOT IN
(SELECT max(ctid) FROM customers GROUP BY customers.*);
The default ctid field unique to each entry is hidden, but it is in each table.
The last query is resource-intensive, so be careful when running it on a working project.
Now let’s consider the case when field values are repeated.
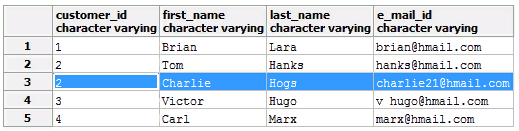
If it is acceptable to delete duplicates without saving all the data, we will execute such a query:
DELETE FROM customers WHERE ctid NOT IN
(SELECT max(ctid) FROM customers GROUP BY customer_id);
If data is important, you must first find duplicate records:
SELECT * FROM customers WHERE ctid NOT IN
(SELECT max(ctid) FROM customers GROUP BY customer_id);

Before deleting, you can transfer such records to a temporary table or replace the customer_id value in them with another.
The general form of a request to delete the records described above looks like this:
DELETE FROM table_name WHERE ctid NOT IN (SELECT max(ctid) FROM table_name GROUP BY column1, [column 2,] );
Safe change of field type
The question may arise about including such a task into this list. After all, in PostgreSQL, it is very easy to change the field type using the ALTER command. Let’s take a look at the customer table again for an example.
For the customer_id field, the string data type varchar is used. This is an error because this field is supposed to store customer_id identifiers, which have integer format. Using varchar is unreasonable. Let’s try to fix this misunderstanding with the ALTER command:
ALTER TABLE customers ALTER COLUMN customer_id TYPE integer;
But we will get an error as a result of execution:
ERROR: column “customer_id” cannot be cast automatically to type integer
SQL state: 42804
Hint: Specify a USING to perform the conversion.
This means that you cannot just change the field type if you have data in the table. Since the varchar type was used, the DBMS cannot determine if the value belongs to an integer. Although the data corresponds to this very type. To clarify this point, the error message suggests using the USING expression to correctly convert our data to an integer:
ALTER TABLE customers ALTER COLUMN customer_id TYPE integer USING (customer_id::integer);
As a result, everything went smoothly:
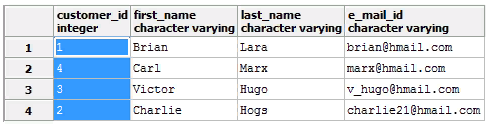
Note that when using USING, it is possible to use functions, other fields and operators besides a specific expression.
For example, convert the customer_id field back to varchar, but with data format conversion:
ALTER TABLE customers ALTER COLUMN customer_id TYPE varchar USING (customer_id || '-' | first_name);
This will make the table look like this:
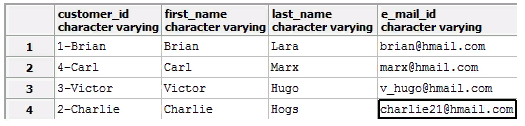
Search for values
Be careful when using sequences as a primary key: when assigned, some elements of a sequence are accidentally skipped, and some records are deleted as of a result of working with the table. You can use such values again, but it is difficult to find them in large tables.
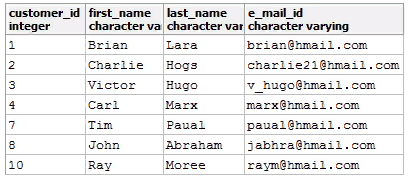
Let’s consider two search options.
The first way
Perform the following query to find the beginning of the interval with the “lost” value:
SELECT customer_id + 1
FROM customers mo
WHERE DOES NOT EXIST
(
SELECT NULL
FROM customers mi
WHERE mi.customer_id = mo.customer_id + 1
)
ORDER BY customer_id;
The result will be the values: 5, 9, and 11.
If we need to find not only the first occurrence but all the missing values, we use the next (resource-intensive!) query:
WITH seq_max AS (
SELECT max(customer_id) FROM customers
),
seq_min AS (
SELECT min(customer_id) FROM customers
)
SELECT * FROM generate_series((SELECT min FROM seq_min),(SELECT max FROM seq_max))
EXCEPT
SELECT customer_id FROM customers;
As a result, we see the following result: 5, 9, and 6.
The second way
We get the name of the sequence associated with customer_id:
SELECT pg_get_serial_sequence('customers', 'customer_id');
And we find all the missing identifiers:
WITH sequence_info AS (
SELECT start_value, last_value FROM "SchemaName". "SequenceName".
)
SELECT generate_series ((sequence_info.start_value), (sequence_info.last_value))
FROM sequence_info
EXCEPT
SELECT customer_id FROM customers;
Counting the number of rows in a table
The number of lines is calculated by the standard count function, but it can be used with additional conditions.
The total number of rows in the table:
SELECT count(*) FROM table;
The number of rows provided that the specified field does not contain NULL:
SELECT count(col_name) FROM table;
The number of unique rows in the specified field:
SELECT count(distinct col_name) FROM table;
Transaction usage
The transaction combines a sequence of actions into one operation. Its peculiarity is that in case of an error in the transaction execution, none of the action results will be saved in the database.
- Let us start the transaction using the BEGIN command.
- To roll back all operations located after BEGIN, use the ROLLBACK command.
- The COMMIT command shall be used to apply the ROLLBACK command.
Viewing and finishing executable queries
In order to get information about the requests, let’s execute the following command:
SELECT pid, age(query_start, clock_timestamp()), usename, query
FROM pg_stat_activity
WHERE query != '<IDLE>' AND query NOT ILIKE '%pg_stat_activity%'.
ORDER BY query_start desc;
In order to stop a specific query, let’s execute the following command with the process id (pid):
SELECT pg_cancel_backend(procpid);
To stop the query, let’s execute it:
SELECT pg_terminate_backend(procpid);
Working with configuration
Search and change the location of a cluster instance
It is possible that several 15 PostgreSQL instances are configured on one operating system, which “sit” on different ports. In this case, finding a way to physically locate each instance is quite a nervous task. In order to get this information, let us perform the following query for any database of the cluster of interest:
SHOW data_directory;
Change the location to another using the command:
SET data_directory to new_directory_path;
But a reboot is required for the changes to take effect.
Getting a list of available data types
Let’s get a list of available data types using the command:
SELECT typname, typlen from pg_type where typtype='b';
- typname is the name of the data type;
- typlen is the size of the data type.
Changing DBMS settings without rebooting
PostgreSQL settings are in special files like postgresql.conf and pg_hba.conf. After changing these files, the DBMS should get the settings again. For this purpose, the database server shall be rebooted.
It is clear that you have to do this, but for the production version of the project, which is used by thousands of users, this is very undesirable. Therefore, in PostgreSQL there is a function with which you can apply changes without rebooting the server:
SELECT pg_reload_conf();
But unfortunately, it does not apply to all parameters. In some cases, a reboot is mandatory to apply the settings.
We looked at commands that will help simplify the work of developers and database administrators using PostgreSQL. But these are not all possible techniques. If you have encountered interesting tasks, please write about them in the comments. Let’s share a useful experience!
Learn 15 PostgreSQL Tutorial Full Course
Enteros
About Enteros
IT organizations routinely spend days and weeks troubleshooting production database performance issues across multitudes of critical business systems. Fast and reliable resolution of database performance problems by Enteros enables businesses to generate and save millions of direct revenue, minimize waste of employees’ productivity, reduce the number of licenses, servers, and cloud resources and maximize the productivity of the application, database, and IT operations teams.
The views expressed on this blog are those of the author and do not necessarily reflect the opinions of Enteros Inc. This blog may contain links to the content of third-party sites. By providing such links, Enteros Inc. does not adopt, guarantee, approve, or endorse the information, views, or products available on such sites.
Are you interested in writing for Enteros’ Blog? Please send us a pitch!
RELATED POSTS
Optimizing Database Performance and Cloud FinOps in the Insurance Sector with Enteros and AWS CloudFormation
- 3 April 2025
- Database Performance Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Driving Growth and RevOps Efficiency in the Technology Sector with Enteros
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Enhancing Healthcare Efficiency with Enteros: AIOps-Driven Database Performance Monitoring
- 2 April 2025
- Database Performance Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Optimizing Cost Estimation and RevOps Efficiency with Enteros: Enhancing Financial Stability and Balance Sheet Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…