Preamble

Many developers, even those who have long been familiar with SQL, do not understand window functions, considering them some kind of special magic for the chosen ones. And although the implementation of window functions is supported with SQL Server 2005, someone is still “copying” them from StackOverflow without going into details.
With this article, we will try to debunk the myth about the impregnability of this SQL functionality and show some examples of window functions on the real dataset.
Why not GROUP BY and JOIN
Let us make it clear at once that window functions are not the same as GROUP BY. They do not reduce the number of lines but return the same values as they received at the input. Secondly, unlike GROUP BY, OVER can refer to other lines. And thirdly, they can read moving averages and cumulative sums.
Note Window functions do not change the selection, but only add some additional information about it. For ease of understanding, you can assume that SQL first executes the entire query (except sorting and limit), and then reads the window values.
Okay, GROUP BY has been dealt with. But you can almost always go several ways in SQL. For example, you may want to use subqueries or JOIN. Of course, JOIN is preferable to subqueries for performance, and the performance of JOIN and OVER constructs will be the same. But OVER gives more freedom than a rigid JOIN. And the size of the code will end up being much smaller.
For starters
Window functions start with the OVER operator and are configured with three other operators: PARTITION BY, ORDER BY, and ROWS. We will tell you more about ORDER BY, PARTITION BY and its auxiliary operators LAG, LEAD, RANK.
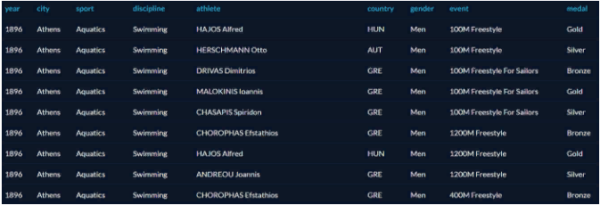
All examples will be based on Datacamp’s Olympic medalist dataset. The table is called summer_medals and contains the results of the Olympics from 1896 to 2010:
ROW_NUMBER and ORDER BY
As mentioned above, the OVER operator creates a window function. Let us start with a simple function ROW_NUMBER, which assigns a number to each selected record:
SELECT
athlete,
event,
ROW_NUMBER() OVER() AS row_number
FROM Summer_Medals
ORDER BY row_number ASC;

Each pair of “sportsman – sport” received a number, and these numbers can be accessed by the name of row_number.
ROW_NUMBER can be combined with ORDER BY to determine in which order the lines will be numbered. Let us select all available sports with DISTINCT and number them in alphabetical order:
SELECT
sport,
ROW_NUMBER() OVER(ORDER BY sport ASC) AS Row_N
FROM (
SELECT DISTINCT sport
FROM Summer_Medals
) AS sports
ORDER BY sport ASC;

PARTITION BY and LAG, LEAD, and RANK
PARTITION BY allows you to group rows by the value of a particular column. This is useful if the data is logically divided into some categories and something needs to be done with this row taking into account other rows of the same group (say, to compare a tennis player with other tennis players, but not with runners or swimmers). This operator works only with window functions like LAG, LEAD, RANK, etc.
LAG
The LAG function takes a string and returns the one that went before it. For example, we want to find all Olympic tennis champions (men and women separately) since 2004, and for each of them find out who was the previous champion.
It takes several steps to solve this problem. First, we need to create a tabular expression that will save the result of the query “tennis champions since 2004” as a temporary named structure for further analysis. And then divide them by sex and select the previous champion using LAG:
-- Tabular expression searches for tennis champions and selects the required columns
WITH Tennis_Gold AS (
SELECT
Athlete,
Gender,
Year,
Country
FROM
Summer_Medals
WHERE
Year >= 2004 AND
Sport = 'Tennis' AND
event = 'Singles' AND
Medal = 'Gold')
-- The window function divides by the floor and takes the champion from the previous line
SELECT
Athlete as Champion,
Gender,
Year,
LAG(Athlete) OVER (PARTITION BY gender)
ORDER BY Year ASC) AS Last_Champion
FROM Tennis_Gold
ORDER BY Gender ASC, Year ASC;
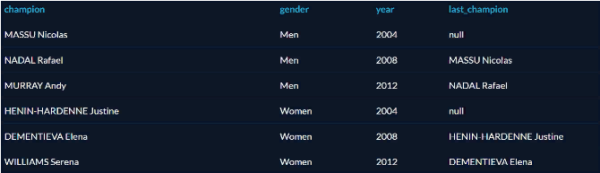
The PARTITION BY function in the table returned first all men, then all women. For the winners of 2008 and 2012, the previous champion is given; since the data are only for 3 Olympiads, the 2004 champions have no predecessors, so in the corresponding fields is null.
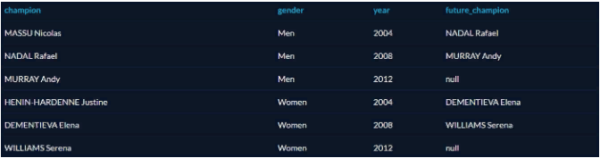
LEAD
The LEAD function is similar to LAG but returns the next line instead of the previous one. You can find out who became the next champion after this or that athlete:
-- Tabular expression searches for tennis champions and selects the required columns
WITH Tennis_Gold AS (
SELECT
Athlete,
Gender,
Year,
Country
FROM
Summer_Medals
WHERE
Year >= 2004 AND
Sport = 'Tennis' AND
event = 'Singles' AND
Medal = 'Gold')
-- The window function divides by the floor and takes the champion from the following line
SELECT
Athlete as Champion,
Gender,
Year,
LEAD (Athlete) OVER (PARTITION BY gender)
ORDER BY Year ASC) AS Future_Champion
FROM Tennis_Gold
ORDER BY Gender ASC, Year ASC;
RANK
The RANK operator is similar to ROW_NUMBER, but assigns the same numbers to the lines with the same values, and skips the “extra” numbers. There is also DENSE_RANK, which does not skip numbers. This sounds confusing, so it is easier to show it by example.
Here is the ranking of countries by the number of Olympiads they participated in by different operators:
![]()
- Row_number – nothing interesting, the lines are simply numbered in ascending order.
- Rank_number – rows are ranked in ascending order, but no number 3. Instead, 2 lines divide the number 2, followed immediately by number 4.
- Dense_rank – the same as rank_number, but number 3 is not missing. The numbers go in a row, but no one is the fifth of the five.
Here is the code:
-- The tabular expression selects the countries and counts the years
WITH countries AS (
SELECT
Country,
COUNT(DISTINCT year) AS
FROM
Summer_Medals
WHERE
Country in ('GBR', 'DEN', 'FRA', 'ITA', 'AUT')
GROUP BY
Country)
-- Different window functions rank countries
SELECT
Country,
This is the case,
ROW_NUMBER()
OVER(ORDER BY DESC) AS Row_Number,
RANK()
OVER(ORDER BY DESC) AS Rank_Number,
DENSE_RANK()
OVER(ORDER BY DESC) AS Dense_Rank
FROM countries
ORDER BY DESC;
That’s how we arranged this dataset into shelves using window functions. That’s where our introduction to window functions ends. We hope it was interesting and not as difficult as it might seem.
Of course, this is not all the possibility of window functions. There are many other useful things for them, such as ROWS, NTILE, and aggregation functions (SUM, MAX, MIN, and others), but we will talk about it another time.
SQL window functions
The views expressed on this blog are those of the author and do not necessarily reflect the opinions of Enteros Inc. This blog may contain links to the content of third-party sites. By providing such links, Enteros Inc. does not adopt, guarantee, approve, or endorse the information, views, or products available on such sites.
Are you interested in writing for Enteros’ Blog? Please send us a pitch!
RELATED POSTS
Streamlining Legal Sector Operations: Enteros for Cloud Resource Optimization, Backlog Prioritization, and Cloud FinOps Excellence
- 25 December 2024
- Database Performance Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Optimizing DevOps and Cloud FinOps for the Pharmaceutical Sector: Enhancing Database Performance and Cost Efficiency with Enteros
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Revolutionizing Cost Allocation and Attribution in Real Estate with Enteros: Optimizing Database Performance for Better Financial Insights
- 24 December 2024
- Database Performance Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Enteros: Streamlining Root Cause Analysis and Shared Cost Optimization with Cloud FinOps in the Public Sector
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…