NoSQL

NoSQL is an approach to the implementation of scalable storage (database) of information with a flexible data model that differs from the classical relational DBMS.
In non-relational databases, the problems of scalability and availability, important for Big Data, are solved by atomicity and consistency.
Why do we need non-relational databases in Big Data: History of appearance and development
NoSQL databases are optimized for applications that need to process large amounts of data with different structures quickly, with low latency. Thus, non-relational storages are directly oriented to Big Data. However, the idea of databases of this type originated much earlier than the term “big data”, back in the 80s of the last century, during the first computers (mainframes) and was used for hierarchical directory services.
The modern understanding of NoSQL-DBMS emerged in the early 2000s, as part of the creation of parallel distributed systems for highly scalable Internet applications, such as online searches.
In general, the term NoSQL means “not only SQL”. (Not Only SQL), characterizing the branch from the traditional approach to database design. Initially, this was the name of the oppositional database created by Carlo Strozzi, which stored all data as ASCII-files, and instead of SQL-queries to access the data used shell scripts.
In the early 2000s, Google built its search engine and applications (Gmail, Maps, Earth, and other services), solving problems of scalability and parallel processing of large volumes of data. Thus, distributed file and coordination systems as well as column family storage based on the MapReduce computing model were created.
After Google Corporation published a description of these technologies, they became very popular among open-source software developers. As a result, Apache Hadoop was created and the main related projects were launched. For example, in 2007, another IT giant, Amazon.com, published articles about its highly available Amazon DynamoDB database.
Then, this race of NoSQL technologies for managing large data included many corporations: IBM, Facebook, Netflix, eBay, Hulu, Yahoo! and other IT companies with their proprietary and open solutions.

Diversity of NoSQL Solutions
What are NoSQL DBMS: the main types of non-relational databases
All NoSQL decisions are divided into 4 types:
Key-value
Key-value – the simplest variant of data storage that uses the key to access the value within a large hash table.
Such DBMS is used for image storage, creation of specialized file systems, as caches for objects, as well as in scalable Big Data systems, including gaming and advertising applications, and projects of Internet of Things (Internet of Things, IoT), including industrial (Industrial IoT, IIoT).
The most famous representatives of non-relational key-value type DBMS are Oracle NoSQL Database, Berkeley DB, MemcacheDB, Redis, Riak, Amazon DynamoDB, which support high separability, providing an unprecedented horizontal scaling, which is unattainable when using other types of databases.
Document oriented storage
Document oriented storage, where data represented by key-value pairs are compressed as a semi-structured document from tagged elements like JSON, XML, BSON and other similar formats. This model is well suited for catalogs, user profiles, and content management systems, where each document is unique and changes over time.
Therefore, document NoSQL DBMS is most often used in CMS systems, publishing, and documentary search. The brightest examples of document-oriented non-relational databases are CouchDB, Couchbase, MongoDB, eXist, Berkeley DB XML.
Column storage
Column storage, which stores information as a sparse matrix, with rows and columns used as keys. In the world of Big Data, column storage refers to databases such as the Column Family. In such systems, the values themselves are stored in columns (columns) represented in separate files.
Thanks to this data model, a large number of attributes can be stored in a compressed form, which speeds up the execution of database queries, especially the data search and aggregation operations. The availability of timestamps enables us to use such DBMS for the organization of counters, registration, and processing of events related to time: exchange analytics systems, IoT/IIoT applications, content management systems, etc. The most famous column database is Google Big Table, as well as Apache HBase and Cassandra based on it. This type also includes the less popular ScyllaDB, Apache Accumulo, and Hypertable.
Graph Storage
Graph Storage is a network database that uses nodes and ribs to display and store data. Since the edges of the graph are stored, bypassing the graph does not require additional calculations (as a connection in SQL). In this case, indexes are required to find the initial vertex of the bypass.
Usually, graphical DBMS supports ACID requirements and specialized query languages (Gremlin, Cypher, SPARQL, GraphQL, etc.). Such DBMS is used in communication-oriented tasks: social networks, fraud detection, public transport routes, road maps, network topologies.
Examples of graph databases: InfoGrid, Neo4j, Amazon Neptune, OrientDB, AllegroGraph, Blazegraph, InfiniteGraph, FlockDB, Titan, ArangoDB.
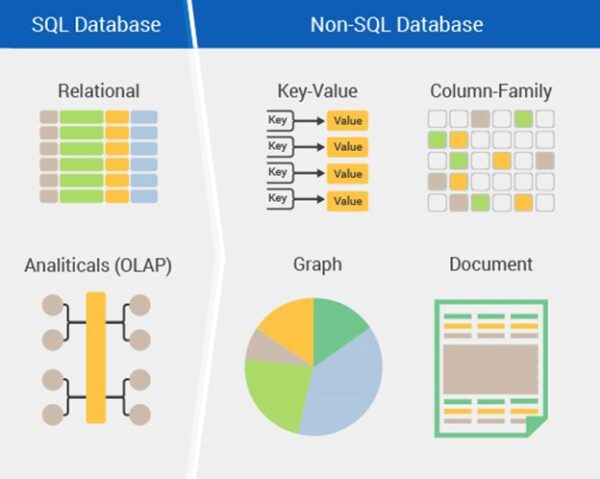
Types of NoSQL DBMS
The good and bad of non-relational databases: the main advantages and disadvantages
In comparison with classical SQL databases, non-relational DBMS has the following advantages:
- linear scalability – adding new nodes to the cluster increases the overall system performance;
- flexibility, which allows operating semi-structured data, implementing, including full-text search in the database;
- the ability to work with different views of information, including without specifying the data layout;
- high availability due to data replication and other fault-tolerance mechanisms, in particular, sharing – automatic data division into different nodes of the network, when each server of the cluster is responsible only for a certain set of information, processing requests for its reading and writing. This increases the data processing speed and bandwidth of the application;
- performance through optimization for specific types of data models (document, graph, column or “key-value”) and access templates;
- wide functionality – own SQL-like query languages, RESTful-interfaces, API, and complex data types, for example, map, list, and struct, which allow processing many values at once.
The reverse side of the above-mentioned advantages is the following disadvantages:
- the limited capacity of the built-in query language. For example, HBase provides only 4 functions of work with data (Put, Get, Scan, Delete), in Cassandra, there are no operations Insert and Join, despite the presence of SQL-like query language. To solve this problem, use third-party means of translating classic SQL-examples into the execution code for a specific non-relational database. For example, Apache Phoenix for HBase or the universal Drill;
- difficulties in supporting all ACID requirements for transactions (atomicity, consistency, isolation, durability) due to the fact that NoSQL-DBMS instead of CAP-model (consistency, availability, separation resistance) rather corresponds to the BASE model (basic availability, flexible state, and final consistency);
- However, some non-relational DBMS try to bypass this restriction with the help of configurable consistency levels, as we described in the Cassandra example. Similarly, Riak allows setting the required availability-coherence characteristics even for individual queries by specifying the number of nodes required to confirm the successful completion of the transaction. More details about CAP and BASE models will be presented in a separate article;
- Strong application binding to a specific DBMS due to the specifics of the internal query language and flexible case-oriented data model;
- lack of specialists in NoSQL databases in comparison with relational analogs.
Summing up the description of the main aspects of non-relational DBMS, it is worth noting some incorrectness of the “NoSQL vs SQL” query due to different architectural approaches and application tasks, which these IT tools are oriented at.
Traditional SQL databases perfectly cope with the processing of strictly typed information of not too large volume. For example, a local ERP system or cloud CRM. However, in the case of processing a large volume of semi-structured and unstructured data, i.e.
Big Data, in a distributed system, should be selected from a variety of NoSQL-storage, taking into account the specifics of the task itself. In particular, for independent solutions of the Internet of Things (Internet of Things), including industrial, perfectly suits Cassandra, which we discussed here.
And in the case of multi-level IT infrastructure based on Apache Hadoop, it is worth paying attention to HBase, which allows you to quickly, almost in real-time, to work with data stored in HDFS.
An Introduction To NoSQL Databases
Enteros
About Enteros
IT organizations routinely spend days and weeks troubleshooting production database performance issues across multitudes of critical business systems. Fast and reliable resolution of database performance problems by Enteros enables businesses to generate and save millions of direct revenue, minimize waste of employees’ productivity, reduce the number of licenses, servers, and cloud resources and maximize the productivity of the application, database, and IT operations teams.
The views expressed on this blog are those of the author and do not necessarily reflect the opinions of Enteros Inc. This blog may contain links to the content of third-party sites. By providing such links, Enteros Inc. does not adopt, guarantee, approve, or endorse the information, views, or products available on such sites.
Are you interested in writing for Enteros’ Blog? Please send us a pitch!
RELATED POSTS
Maximizing IT Sector Efficiency: How Enteros Enhances Database Optimization, Cloud FinOps, and RevOps Alignment
- 10 April 2025
- Database Performance Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Optimizing RevOps and AIOps in the Manufacturing Sector with Enteros Database Performance Platform
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Enhancing Database Performance on Azure Cloud for the Fashion Industry with Enteros
- 9 April 2025
- Database Performance Management
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…
Enhancing DevOps Efficiency in the E-commerce Sector with Enteros Observability Platform
In the fast-evolving world of finance, where banking and insurance sectors rely on massive data streams for real-time decisions, efficient anomaly man…